第一章 走入并行世界
介绍 没有什么需要记的
第二章 Java并发程序基础
2.1线程的六个基本状态
NEW RUNNABLE BLOCKED,WAITING,TIMED_WAITING,TERMINATED
2.2 线程基本操作
2.2.1 新建线程
一些简单的基本的耗字的就不写了
这里主要是Thread与Runnable区别 以及Start开始线程方法 推荐使用Runnable接口进行编写并发代码 这也是最常见的方式
2.2.2 终止线程
stop方法(该方法会立即终止该线程)被废弃了 原因是太过暴力 可能导致数据不一致的问题
因为在stop方法会立即结束锁然后立即释放锁 而这些锁是用来维持对象的一致性的 如果写数据写到一半 并强行终止的话 那么对象就会被写坏 另外一个等待该锁的就会读到这个不一致的对象 悲剧就发生了
相关代码请见 StopThreadUnsafe
那怎么改进呢才合适呢 其实只需要自己决定线程何时退出就可以了
增加一个stopMe的volatile字段 再自定义一个是否StopMe的方法
相关代码请见 StopThreadSafe
2.2.3 线程中断
在java中 线程中断是一个重要的线程协作机制 中断就是让目标线程停止运行的意思 实际并非如此 严格的讲 线程中断并不会使线程退出 而是给线程发送一个通知 告知目标线程 有人希望你退出 至于目标线程接到通知如何处理 则完全由目标线程自己决定 如果中断后 无条件退出 就会遇到stop方法的老问题
与中断线程有关的三个方法
interrupt() //中断线程
isInterrupted() //判断是否中断
interrupted() //判断是否被中断 并清除当前中断状态
中断方法乍看与上面的stop标记的手法非常相似 但是中断更为强力 比如 如果在循环体中 出现了类似wait()或者sleep()这样的操作 则只能用中断来识别了
相关代码请见 InterruptTest
2.2.4 等待与通知
wait方法与notify方法
notify是随机的唤醒一个线程 notifyAll会唤醒所有等待的线程这俩个方法的关键在一个监听器 在使用wait方法前必须获得object对象的监听器 wait方法执行后 会释放这个监听器 这样做的目的是使得其他等待在object对象上的线程不至于因为第一个线程的休眠而全部无法正常执行 在第二个线程使用notify前也必须获得一个object的监听器 然后获得这个监听器后 notify就会尝试去唤醒一个等待线程 在线程被唤醒后 第一件事是尝试获得这个监听器 而不是执行后续代码 如果暂时无法获得 就等待这个监听器 获得了之后 才能真正的继续执行
相关代码请见 SimpleWN
2.2.5 suspend与resume方法
suspend与resume方法 现在已经是不推荐的操作了 不推荐使用的原因是suspend会导致线程暂停的同时 不会去释放任何锁资源 此时 其他任何线程想要访问被它暂用的锁时 都会被牵连 导致无法正常运行 直到对应的线程上进行了resume操作 被挂起的线程才能继续 从而其他所有阻塞在相关锁上的线程也可以继续执行 但是,如果resume操作意外的在suspend之前的执行了 那么挂起的线程很难有机会继续执行 并且 它占用的锁不会释放 因此可能会导致整个系统工作不正常 而且 对于被挂起的线程 从它的线程状态来看 居然还是Runnable 也会严重影响对系统当前状态的判断
相关代码请见 BadSuspend
如果需要一个可靠的suspend函数的话 可以利用wait与notify方法
给出一个标记变量suspendMe 表示当前线程是否被挂起 同时增加了suspendMe和resumeMe俩个方法 分别用于挂起线程与继续执行线程
相关代码请见 GoodSuspend
2.2.6 等待线程结束(join)与谦让(yield)
Join有俩个不同参数的方法
一个是默认的无限等待 一直阻塞当前线程 直到目标线程执行完毕
第二个方法给出了一个最大等待时间 如果超过给定时间目标线程还在执行 当前线程也会因为“等不及了”,而继续往下执行
相关代码请见 JoinMain
有关Join 补充一点 join的本质是让调用线程wait在当前线程对象实例上
下面是JDK中join实现的核心代码片段while(isAlive()){
wait(0);
}
可以看到 它让调用线程在当前线程对象上进行等待 当线程执行完成后 被等待的线程也会在退出前调用notifyAll()通知所有的等待线程继续执行 因此 值得注意的一点是:不要在应用程序中 在Thread的对象实例上使用类似wait()或者notify()等方法 因为这很有可能会影响到系统API的 或者被系统API所影响
Thread.yield()方法 它的定义如下
1 | public static native void yield(); |
这是一个静态方法 一旦执行 它会使当前线程让出CPU 但要注意 让出CPU并不表示当前线程不执行了 当前线程在让出CPU后 还会执行CPU资源的争夺 但是是否能够被再次分配到 就不一定了 因此 对Thread.yield调用就好像是在说:我已经完成了一些重要的工作 我应该是可以休息一下了 ,可以给其他线程一些工作机会了
如果你觉得一个线程不是那么重要 或者优先级非常低 而且又害怕它会占用太多的CPU资源 那么可以在适当的时候调用Thread.yield() 给予其他重要线程更多的工作机会
2.3 volatile与Java内存模型(JMM)
volatile的语义是 易变的 不稳地的 这也正是使用volatile关键字的语义
当你使用volatile去声明一个变量时 就等于告诉了虚拟机 这个变量极有可能会被某些程序或者线程修改 为了确保这个变量被修改后 应用程序范围内的所有线程都能够“看到”这个改动,虚拟机就必须采用一些特殊的手段 保证这个变量的可见性等特点
volatile对保证操作的原子性是有非常大的帮助的 但是 需要注意的是,volatile并不能代替锁 ,它也无法保证一些复合操作的原子性
相关代码请见 VolatileAtomicTest
volatile也可以保证数据的可见性和有序性
相关代码请见 NoVisibility
2.4分门别类的管理:线程组
相关代码请见 ThreadGroupName
2.5 驻守后台:守护线程(Daemon)
守护线程是一种特殊的线程 就和它的名字一样 它是系统的守护者 在后台默默地运行一些系统性的服务 比如垃圾回收线程 JIT线程就可以理解为守护线程 与之相对应的就是用户线程 用户线程可以认为是系统的工作线程 它会完成这个程序应该要完成的业务操作 如果用户线程全部结束了 这意味着这个程序实际上无事可做了 守护线程要守护的对象已经不存在 那么整个应用程序就自然应该结束 因此 当一个Java应用内 只有守护线程时 Java虚拟机就会自然退出
相关代码请见 DaemonDemo
守护线程必须在线程start()之前设置 否则会得到一个IllegalThreadStateException异常 然后程序和线程依然可以运行 只不过被当做了用户线程而已
2.6 先干重要的事:线程优先级
Java的线程可以有自己的优先级 优先级高的在竞争线程时会更有优势 更可能抢占资源 当然 这只是一个概率问题 运气不好 也抢不到 这个线程的优先级调度和底层操作系统有密切的关系 在各个平台上表现不一 并且这种优先级产生的后果也可能不容易预测 无法精准控制 因此 在要求严格的场合 还是需要自己在应用层解决线程调度问题
在Java中使用1-10表示线程优先级 一般可以使用内置的三个静态标量表示
1 | public final static int MIN_PRIORITY = 1; |
数字越高则优先级越大 但有效范围在1-10 高优先级的线程倾向于更快的完成
相关代码请见 PriorityDemo
2.7 线程安全的概念与synchronized
volatile不能真正保证线程安全 它只能确保一个线程修改了数据后 其他线程能够看到这个改动 但当俩个线程同时修改某一个数据时 却依然会产生冲突
相关代码请见 AccountingVol
要从根本解决这个问题 我们就必须保证多个线程对i进行操作时完全同步 也就是说 当线程A在写入时 线程B不仅不能写 同时也不能读 因为在线程A写完之前 线程B读取的一定是一个过期数据 Java中 提供了一个重要的关键字synchronized来实现这个功能
关键字synchronized的作用是实现线程间的同步 它的工作是对同步的代码加锁 使得每一次 只有一个线程进入同步代码块 从而保证线程间的安全性
关键字synchronized的可以有多种用法 这里做一个简单的整理
- 指定加锁对象:对给定对象加锁 进入同步代码前要获得给定对象的锁
- 直接作用域实例对象:相当与对当前实例加锁,进入同步代码钱要获得当前实例的锁
- 直接作用域静态方法:相当于对当前类加锁 进入同步代码前要获得当前类的锁
相关代码请见 AccountingSync
一种错误的加锁方式
相关代码请见 AccountingSyncBad
除了用于线程同步,确保线程安全外,synchronized还可以保证线程间可见性和有序性 从可见性的角度上讲 synchronized可以完全替代volatile的功能 只是使用上没有volatile方便 就有序性而言 由于synchronized限制的代码都是串行执行的所以不用担心有序性问题
2.8 程序中的幽灵:隐蔽的错误
2.8.1 无提示的错误案例
1 | int v1=1073741827; |
这里就会出现一个错误 这个错误是因为int的溢出问题 这种问题就是无提示的错误案例 这种问题非常难找 不能得到异常与相关的错误日志
2.8.2 并发下的ArrayList
相关代码请见 ArrayListMultiThread
这里会出现三种结果
- 正常结束 最终大小确实2000000
- 抛出一个越界异常 这是因为ArrayList在扩容过程中 内部的一致性被破坏,但没有锁的保护 另一个线程访问到了不一致的内部状态 导致出现了越界问题
- 出现了一个非常隐蔽的错误 出现了一个值 比如 1793758
这个是由于多线程访问冲突 使得保存容器大小的变量被多线程不正常的访问 同时俩个线程也同时对ArrayList的同一个位置进行赋值导致的 这种问题 很不幸 是没有错误提示的错误 而且 也不一定能复现
2.8.3 并发下诡异的HashMap
相关代码请见 HashMapMultiThread
这里在Jdk8之前的系统中会出现3个问题
- 程序正常结束 结果也正常
- 程序正常结束 结果不正常
- 程序永远无法结束
第3个问题在JDK8中被修复了 即使这样 贸然使用HashMap依然会导致内部数据不一致 最简单的解决方案是使用ConcurrentHashMap
2.8.4 初学者常见问题:错误的加锁
相关代码请见 BadLockOnInteger
这个问题其实就是加错了锁 内部的Integer对象是一个不变对象 每次赋值都是创造一个新的对象 所以换个锁对象就好
第三章 JDK并发包
这章的难点在于解析并发包下并发容器的源码
其中主要还是ConcurrentLinkedQueue类
3.1 多线程的团队控制:同步控制
3.1.1 synchronized的功能扩展 :重入锁
重入锁完全替代synchronized关键字 在JDK 5.0早期的版本中 重入锁的性能远远好过synchronized 不过JDK6开始 JDK在synchronized做了大量的优化 使得俩者性能差距不大
重入锁简单的使用案例入戏
相关代码请见 ReenterLock
与synchronized相比 重入锁有着显示的操作过程 也是因为这样 重入锁对逻辑控制的灵活性要远远好于synchronized 但值得注意的是,在退出临界区时 必须记得释放锁 否则 其他线程就别想访问临界区了
为什么要重入锁 因为锁是可以重入 也就是反复进入的
1 | lock.lock(); |
在这种情况下 一个线程连续俩次获得同一把锁 是允许的 如果不允许这么操作的话 那么同一个线程在第二次获得锁时就会死锁 但是需要注意的是 如果同一个线程多次获得锁 那么在释放锁的时候 也必须释放相同次数 如果释放锁的次数多 那么会得到一个IllegalMonitorStateException异常 反之 如果锁释放的次数少了 那么相当于线程还持有这个锁 因此 其他线程也无法进入临界区
除了上面的灵活性外 重入锁还提供了一些高级功能 比如 重入锁就提供中断处理的能力
中断响应
对于synchronized来说 如果一个线程等待锁 那么结果只有俩种情况 要么继续执行 要么它就是保持等待
而使用重入锁 则提供了另外一种可能 那就是线程可以被中断 也就是在等待锁的过程中 程序可以根据需要取消对锁的请求。 有些时候 这么做是非常有必要的
中断正式提供了一套机制 如果一个线程正在等待锁 那么它依旧可以收到一个通知 被告知元素是否再等待 可以停止工作了 这种情况对处理死锁是有一定帮助的
下面的代码产生了一个死锁 但得益与锁中断 我们可以很轻易的解决这个死锁
相关代码请见 IntLock
在这个代码中 统一使用lockInterruptibly()方法
这是一个可以对中断进行响应的锁申请操作 即在等待锁的过程中 可以响应中断
锁申请等待限时
除了等待外部通知 要避免死锁还有另外一种方法 那就是限时等待 给定一个等待时间 让线程自动放弃 这对系统来说是有意义的 我们可以使用tryLock方法进行一次限时的等待
相关代码请见 TimeLock
ReentrantLock.tryLock()方法也可以不带参数直接运行 在这种情况下 当前线程会尝试获得锁 如果锁并未被其他线程占用 则申请锁会成功 并立即返回true 如果锁被其他线程占用 则当前线程不会进行等待 而是立即返回false
这种模式不会引起线程等待 因此也不会产生死锁
相关代码请见TryLock
公平锁
公平锁不会产生饥饿 只要你排队 最终还是可以得到资源的 如果我们使用synchronized关键字来实现锁控制 那么产生的锁就是非公平的 而重入锁允许我们队其公平性进行设置
相关代码请见 FairLock
公平锁看起来的确非常的优美 但是实现公平锁必然要求系统维护一个有序队列 因此公平锁的实现成本比较高 性能也相对非常低下 因此 默认情况下 锁是非公平的 如果没有特别的需求 也不需要使用公平锁 公平锁和非公平锁在线程调度上也是非常不一样的
就重入锁的实现来看 主要集中在Java层面 在重入锁的实现中 主要包含3个元素
- 原子状态 原子状态使用CAS操作来存储当前所的状态 判断锁是否被别的线程持有
- 等待队列 所有没有请求到锁的线程 会进入等待队列进行等待 待有线程释放锁后 系统就能从等待对象唤醒一个线程 继续工作
- 阻塞原语pack()和unpack() 用来挂起和恢复线程 没有得到线程的锁会被挂起 有关pack()和unpack的详细介绍 也可以参考阻塞工具类 LockSupport
3.1.2 重入锁的好搭档:Condition条件
Condition是与重入锁相关联的 通过Lock接口(重入锁就实现了这一接口)的Condition newCondition()方法可以生成一个与当前重入锁绑定的Condition实例 利用Condition对象 我们就可以让线程在合适的时间等待 或者在某一个特定的时刻得到通知 继续执行
具体方法查文档‘、吧
例子如下
相关代码请见 ReenterLockCondition
与Object的wait()和notify()方法一样
在signal()方法被调用后 一般需要释放相关的锁 谦让给被唤醒的线程 让他可以继续执行 比如本例的31-33行 就释放了重入锁 如果省略了第33行 那么 虽然已经唤醒了线程t1 但是由于它无法重新获得锁 因而也就无法真正的继续执行
3.1.3 允许多个线程同时访问:信号量
信号量为多线程提供了更为强大的控制方法 广义上说 信号量是对锁的扩展 无论是内部锁synchronized还是重入锁ReentrantLock 一次都只允许一个线程访问一个资源 ,而信号量却可以指定多个线程 同时访问某一个资源 信号量主要提供以下构造函数
1 | public Semaphore(int permist) |
在构建信号量对象时 必须要指定信号量的准入数 即同时能申请多少个许可 每当线程每次只申请一个许可时 这就相当于指定了同时有多少个线程可以访问某一个资源
1 | public void acquire() |
acquire()方法尝试获得一个准入的许可 若无法获得 则线程会等待 直到有线程释放一个许可 或者当前线程被中断 。acquireUninterruptibly()方法和acquire()方法类似 但是不响应中断 tryAcquire()会尝试获得一个许可 如果成功返回true 失败则是false 它不会进行等待 立即返回
release()用于线程访问资源结束后 释放一个许可 以使其他等待许可的线程可以选择资源返回
相关代码请见 SemaphoreDemo
3.1.4 ReadWriteLock 读写锁
ReadWriteLock是JDK5提供的读写分离锁 读写分离锁可以有效的帮助减少锁竞争 以提升系统开销
如果使用重入锁或者内部锁 所有的读读与读写和写写之间都是要串行操作 由于读操作不会对数据完整性造成破坏 这种等待显然是不合理的 所以读写锁就有了发挥功能的余地
下表是对写锁的访问约束
| \ | 读 | 写|
|:— | :—-: |—:|
|读 | 非阻塞 | 阻塞|
| 写 | 阻塞 | 阻塞|
- 读 -读不互斥 读读之间不阻塞
- 读-写互斥:读阻塞写,写也会阻塞读
- 写-写互斥:写写阻塞
相关代码请见 ReadWriteLockDemo
3.1.5 倒计时器:CountDownLatch
这个工具通常用来控制线程等待 它可以让某一个线程等到直到倒计时结束 再开始执行
CountDownLatch的构造函数接受一个整数作为参数 即当前这个计数器的计数个数
1 | public CountDownLatch(int count) |
相关代码请见 CountDownLatchDemo
3.1.6 循环栅栏 :CyclicBarrier
CyclicBarrier是另外一种多线程并发控制实用工具 和CountDownLatch非常类似 它也可以实现线程间的计数等待 但它的功能比CountDownLatch更加复杂且强大
CyclicBarrier可以理解为循环栅栏 栅栏是一种障碍物 前面的Cyclic意为循环 也就是说这个计数器可以反复使用 比如 假设我们将计数器设置为10 那么凑齐第一批10个线程后 计数器将归零 然后继续接着凑齐下一批的10个线程 这就是循环栅栏内在的含义
比CountDownLatch略微强大一些 CyclicBarrier可以接受一个参数作为barrierAction 所谓barrierAction就是当计数器一次计数完成后 系统会执行的动作
1 | public CyclicBarrier(int parties,Runnable barrierAction) |
相关代码请见 CyclicBarrierDemo
这里会抛出俩个异常 一个是InterruptedException 也就是等待中断 线程被中断 这是一个非常通用的异常 第二个异常则是CyclicBarrier的BrokenBarrierException 一旦遇到这个异常 则表示当前的CyclicBarrier已经破损了 可能系统已经没有办法等待所有线程到期了 如果继续等待 可能就是徒劳无功
这个异常就可以避免其他9个线程进行永久的 无谓的等待
3.1.7 线程阻塞工具类:LockSupport
LockSupport是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置上线程让出线程阻塞,和Thread.suspend()相比 它弥补了由于resume()在前发生 导致线程无法继续执行的情况 和Object.wait()相比 它不需要先伙食某发对象的锁 也不会抛出InterruptedException异常
用LockSupport重写第二章提到的suspend()永久卡死线程的例子
相关代码请见 LockSupportDemo
在简单的将原来的suspend()和resume()方法用park()和unpark()方法做了替换 当然也无法保证unpark()方法会发生在park()方法之前 但是 它自始至终都可以正常的结束 不会因为park()方法而导致线程永久性的挂起
这是因为LockSupport类使用类似信号量的机制。它为每一个线程准备了一个许可,如果许可可用 那么park()方法会立即返回 并且消费这个许可(也就是将许可变为不可用) 如果许可不可用 就会阻塞 而unpark()则会使得一个许可变为可用(但是和信号量不同的是,许可不能累加,你不能拥有超过一个许可 它拥有只有一个)
这个特点使得:即使unpark()操作发生在park()之前 它也可以使下一层的park()操作立即返回 这也就是上述代码可顺利结束的主要原因
同时 处于park()挂起状态的显存不会像suspend()那样还给出一个令人费解的Runnable的状态 它会非常明确地给出一个WAITING状态 甚至还会标注是park()引起的
这使得分析问题时变得格外方便 此外 如果你使用park(Object)函数 还可以为当前线程设置一个阻塞对象 这个阻塞对象会出现在线程Dump中 这样在分析问题时 就更加方便了
比如 如果我们将上述代码第21行的park()方法改为
1 | LockSupport.park(this); |
这样在线程dump中就可以看到类似
除了有定时阻塞的功能外 LockSupport.park()还能支持中断影响 但是和其他接受中断的函数很不一样,LockSupport.park()不会抛出InterruptedException异常 它只是会默默的返回 但是我们可以从Thread.interrupted()等方法获得中断标记
相关代码请见 LockSupportIntDemo
3.2 线程复用:线程池
多线程的软件设计方法确实可以最大限度的发挥现代多核处理器的计算能力 提高生产系统的吞吐量和性能 但是 若不加控制和管理的随意使用线程 对系统的性能反而会产生不利影响
首先 虽然与进程相比,线程是一种轻量级的工具。但其创建和关闭依然需要花费时间 如果每一个小的任务都创建一个线程,很有可能出现创建和销毁线程所占用的时间大于该线程真实工作使所消耗时间的情况 反而会得不偿失
其次 线程本身也是要占用内存空间 大量的线程会强占宝贵的内存资源 如果处理不当 可能会导致Out of Memory异常 即便没有 大量的线程回收也给GC代理很大的压力 延长GC的停顿时间
因此 对线程的使用必须掌握一个度 在有限的范围内 增加线程的数量可以明显提高系统的吞吐量 但一旦超出了这个范围 大量的线程只会拖垮应用系统 因此 在生成环境中使用线程 必须对其加以控制和管理
3.2.1 什么是线程池
想仔细了解的查百科吧
对创建的线程进行复用
3.2.2 不要重复发明轮子:JDK对线程池的支持
为了更好的控制多线程 JDK提供了一套Executor框架 帮助开发人员有效地进行线程控制 其本质就是一个多线程

以上成员均在java.util.concurrent包中 是JDK并发包的核心类 其中ThreadPoolExecutor类表示一个线程池 Executors类则扮演着线程池工厂的角色 通过Executors可以取得一个拥有特定功能的线程池 从UML图中可知 ThreadPoolExecutor类实现了Executor接口 因此通过这个接口 任何Runnable的对象都可以被ThreadPoolExecutor线程池调度
Executor 执行器接口,该接口定义执行Runnable任务的方式。
ExecutorService 该接口定义提供对Executor的服务。
ScheduledExecutorService 定时调度接口。
AbstractExecutorService 执行框架抽象类。
ThreadPoolExecutor JDK中线程池的具体实现。
Executors 线程池工厂类
Executor框架提供了各种类型的线程池 主要有以下工厂方法:
1 | public static ExecutorService newFixedThreadPool(int nThreads) |
以上工厂方法分别返回具有不同工作特性的线程池
- newFixedThreadPool()方法 该方法返回一个固定线程数量的线程池 该线程池中的线程数量始终不变 有新任务 若有空线程 就用 没有空线程 这个新任务就放到一个任务队列 等有线程空闲去处理任务队列的任务
- newSingleThreadExecutor()方法:该方法返回一个只有一个线程的线程池 若多就放任务队列 一个个按顺序来
- newCacheThreadPool()方法:该方法返回一个可根据实际情况调整线程数量的线程池 线程池的线程数量不确定 但若有空闲线程可以复用 则会优先使用可复用的线程 若所有线程均在工作 又有新的任务提交 则会创建新的线程处理任务 所有线程在当前任务执行完毕后 将返回线程池进行复用
- newSingleThreadScheduledExecutor()方法:该方法返回一个ScheduledExecutorService对象 线程池大小为1 ScheduledExecutorService接口在ExecutorService接口之上扩展了在给定时间执行某任务的功能
- newScheduledThreadPool()方法:该方法也返回一个ScheduledExecutorService对象 但该线程池也可以指定线程数量
固定大小的线程池
相关代码请见 ThreadPoolDemo
计划任务
另外一个值得注意的是newScheduledThreadPool()方法 它返回一个ScheduleExecutorService对象 可以根据时间需要对现场进行调度 它的一些主要方法如下
public ScheduledFuture<?> schedule(Runnable command,
1
long delay, TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
1
2
3
4
5long initialDelay,
long period,
TimeUnit unit);public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
1
2
3
4
5long initialDelay,
long delay,
TimeUnit unit);
与其他几个线程池不同 ScheduledExecutorService并不一定会立即安排执行任务 它其实是起到了计划任务的作用 它会在指定的时间 对任务进行调度
方法schedule()会在给定时间 对任务进行一次调度 方法scheduleAtFixedRate()和scheduleWithFixedDelay()会对任务进行周期性的调度 但是俩者有一点区别
对于FixedRate方式来说 任务调度的频率是一定的 它是以上一个次任务开始执行时间为起点 之后的period时间 调度下一次任务 而FixDelay则在上一个任务结束后 再经过delay时间进行任务调度 这样说可能会比较模糊
FixRate是隔多长时间周期执行是包括内部代码的运行时间 而FixDelay则是不包括内部代码的运行时间 而是隔多长时间运行一次
具体的话看官方文档吧 以及下面的例子
相关代码请见 ScheduledExecutorServiceDemo
这里有一个有意思的地方 如果任务的执行时间超过调度时间 会发生什么情况呢?比如 这里调度是每隔2秒 如果任务执行8秒 会出现什么情况呢 这种周期太短的情况 那么任务就会在上一个任务结束后 立即被调用 可以想象 如果用FixDelay就会变成10秒了
另外一个值得注意的问题 调度程序实际上并不保证任务会无限期的持续调用 如果任务本身抛出了异常 那么后续所有执行都会中断 因此 如果你想让你的任务持续稳定的执行 那么做好异常处理就非常重要了 否则 你很有可能观察到你的调度器无疾而终
注意 如果任务遇到异常 那么后续的所有子任务都会停止调度 因此 必须保证异常被及时处理 为周期性任务的稳定调度提供条件
3.2.3 刨根究底:核心线程池的内部实现
这个太麻烦就不写多了 就写一些我认为关键的地方
无论是newFixedThreadPool()方法 newSingleThreadExecutor()方法还是newCachedThreadPool()方法 虽然看起来创建的线程有着完全不同的功能特点 但其内部实现均使用了ThreadPoolExecutor实现
1 | public ThreadPoolExecutor(int corePoolSize, |
函数的参数含义如下
- corePoolSize:指定了线程池中的线程数量
- maximumPoolSize:指定了线程池中的最大线程数量
- keepAliveTime:当线程池数量超过corePoolSize时 多余的空闲线程的存活时间 即 超过corePoolSize的空闲线程 在多长时间内 会被销毁
- unit:keepAliveTime的单位
- workQueue:任务队列,被条件但尚未被执行的任务
- threadFactory:线程工厂 用于创建线程 一般使用默认的即可
- handler:拒绝策略 当任务太多来不及处理 如何拒绝服务
上述参数中 只有workQueue和handler需要进行详细说明
参数workQueue是指提交单未执行的任务队列 它是一个BlockingQueue接口的对象 仅用于存放Runnable对象 根据功能介绍 在ThreadPoolExecutor的构造函数中可使用以下几种BlockingQueue
- 直接提交的队列:SynchronousQueue
- 有界的任务队列:ArrayBlockingQueue
- 无界的任务队列:LinkedBlockingQueue
- 优先任务队列:PriorityBlockingQueue
3.2.4 超负载了怎么办:拒绝策略
- AbortPolicy策略:该策略会直接抛出异常 阻止系统正常工作
- CallerRunsPolicy策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降
- DiscardOledestPolicy策略:该策略将丢弃最老的一个请求,也就是即将被执行了的一个任务 并尝试再次提交当前任务
- DiscardPolicy策略:该策略默默地丢弃无法处理的任务,不予任何处理 如果允许任务丢失 我觉得这可能是最好的一种方案了吧
以上内置的策略均实现了RejectedExecutionHandler接口 若以上策略仍无法满足实际应用需要,完全可以自己扩展RejectedExecutionHandler接口,RejectedExecutionHandler的定义如下
1 | void rejectedExecution(Runnable r, ThreadPoolExecutor executor); |
下面的代码简单的演示了自定义线程池和拒绝策略的使用
相关代码请见 RejectThreadPoolDemo
3.2.5 自定义线程创建:ThreadFactory
ThreadFactory是一个借口 它只有一个方法,用来创建线程
1 | Thread newThread(Runnable r) |
当线程池需要新建线程时 就会调用这个方法
自定义线程池可以帮助我们做不少事,比如 等我们可以追踪线程池究竟在何时创建了多少线程,也可以自定义线程的名称,组以及优先级等信息,设置可以任性地将所有线程设置为守护线程。总之,使用自定义线程池可以让我们更加自由地设置池中所有线程的状态
相关代码请见 ThreadFactoryDemo
3.2.6 我的应用我做主:扩展线程池
虽然JDK已经帮我们实现了这个稳定的高性能线程池 但如果我们需要对这个线程池做一些扩展 比如 我们想监控每个任务的开始和结束时间 或者其他一些自定义的增强功能 这个就可以通过ThreadPoolExecutor扩展的功能来实现 它提供了beforeExecutor(),afterExecute()和terminated()三个接口对线程池进行控制
在默认的ThreadPoolExecutor实现中,提供了空的beforeExecute()和afterExecute()实现,在实际应用中。可以对其扩展来实现对线程池运行状态的跟踪 输出一些有用的调试信息, 以帮助系统故障诊断,这对多线程程序输出错误排查是很有帮助的
下面有个例子
相关代码请见 ExTreadPool
3.2.7 合理的选择:优化线程池线程数量
线程池的大小对系统的性能有一定影响 过大或者过小的线程数量都无法发挥最优的性能 但是线程池大小的确定也不需要做的非常精准 因为只要避免极大和极小俩种情况 线程池的带下对系统的性能并不会影响太大 ,一般来说 确定线程池的大小需要考虑CPU数量 内存大小等因素 在《Java Concurrency in Practice》 一书中给出了一个估算线程池大小的经验公式
$$Ncpu=Cpu的数量$$
$$Ucpu=目标CPU的使用率,0<=Ucpu<=1$$
$$W/C=等待时间与计算时间的比率$$
在Java中 可以通过
1 | Runtime.getRuntime().availableProcessors() |
取得可用的CPU数量
3.2.8 堆栈去哪里了:在线程池中寻找堆栈
先看一个简单的错误案例
相关代码请见DivTask
1 | public class DivTask implements Runnable { |
如果程序运行了这个任务,那么我们期望它可以打印出给定俩个数的商。现在我们构造几个这样的任务 希望程序可以为我们计算一组给定数组的商
1 | ThreadPoolExecutor pools = new TraceThreadPoolExecutor(0, Integer.MAX_VALUE, 0L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); |
上述代码将DivTask提交到线程池 从这个for循环来看 我们应该会得到5个结果分别是100除以给定的i后的商 但如果真的运行程序 就发现全部结果是
1 | 33.0 |
只有4个输出 缺少了一个值 这个缺少的值很有可能是由于除以0导致的
因此 使用线程池虽然是件好事 但是还得处处留意这些“坑” 线程池很有可能会“吃”掉程序抛出的异常 导致我们对程序的错误一无所知
向线程池讨回异常堆栈(异常堆栈是非常重要的 类似水手的指南针)
- 一种最简单的方法,就是放弃submit(),改用execute()
- 另外一种用Future对象进行接收
Futere re =pools.submit(new DivTask(100,i));re.get();
上面两种方法都可以得到部分堆栈信息
注意 是部分 这是因为从这俩个异常堆栈中我们只能知道异常是在哪里抛出的 但是我们还希望得到另外一个更重要的信息 那就是这个任务到底是在哪里提交的?而任务的具体提交位置已经被线程池完全淹没了
解决方法就是我们扩展自己的ThreadPoolExecutor线程池 在它调度任务之前 先保存一下提交任务线程的堆栈信息
相关代码请见 TraceThreadPoolExecutor
相关代码请见 DivTask
3.2.9 分而治之:Fork/Join框架
“分而治之”这是一个非常有效的处理大量的数据的方法 也是一个归并排序的实现思想 注明的MapReduce也是采取了分而治之的思想
Fork一词原始含义是吃饭用的叉子 ,也有分叉的意思。在Linux平台中 fork()函数用来创建子进程
使得系统进程可以多一个执行分支。在Java中也沿用了类似的命名方式
而Join()的含义在之前的章节已经介绍 这里也是相同的意思 表示等待 也就是使用fork()后系统多了一个执行分支(线程),所以需要等待这个执行分支执行完毕 才有可能得到最终的结果 因此join()就表示等待
在实际使用中 如果毫无顾忌使用fork()开启线程进行处理 那么很有可能导致系统开启过多的线程而严重影响性能 所以 JDK中 给出一个ForkJoinPool线程池 对于fork()方法并不急着开启线程 而是提交给ForkJoinPool线程池进行处理 以节省系统资源
由于线程池的优化,提交的任务和线程数量并不是一对一的关系。在绝大多数情况下,一个物理线程时间上是需要出来多个逻辑任务的 因此 每个线程必然需要拥有一个任务队列。因此 在实际过程中 会遇到一种情况 线程A已经处理完自己的任务了 但是线程B还有一堆没有处理 于是A就可以去帮助B 从线程B的任务队列拿出一个任务过了处理 尽可能达到平衡
一个值得的地方是 当线程试图帮助别人时 总是从任务队列的底部开始拿数据,而线程视图执行自己的任务时,则是从相反的顶部开始拿 因此这种行为也十分有利于避免数据竞争
ForkJoinPool的一个重要接口
1 | public <T> Future<T> submit(Callable<T> task); |
你可以向ForkJoinPool线程池提交一个ForkJoinTask任务 所谓ForkJoinTask任务就是支持fork()分析以及join()等待的任务 ForkJoinTask有俩个重要的子类,RecursiveAction和RecursiveTask。它们分别表示没有返回值的任务和可以携带返回值的任务
相关代码请见 CountTask
此外,ForkJoin线程池使用了一个无锁的栈来管理空闲线程 如果一个工作线程暂时取不到可用的任务 则可能会挂起 挂起的线程将会被压入线程池维护的栈中 待将来有任务可用时 再从栈中唤醒这些线程
3.3 不要重复的发明轮子:JDK的并发容器
3.3.1 超好用的工具类:并发集合简介
JDK提供的这些容器大部分在java.util.concurrent包中
- ConcurrentHashMap:这是一个高效的并发HashMap 可以理解为一个线程安全的HashMap
- CopyOnWriteArrayList:这是一个List 从名字看是ArrayList一族的 在读多邪少的场合 这个List性能非常好 远远好于Vector
- ConcurrentLinkedQueue:高效的并发队列,使用链表实现 可以看做一个线程安全的LinkedList
- BlockingQueue :这是一个借口 JDK内部通过链表 数组 等方式实现了这个接口 表示阻塞队列 非常适合用于作为数据共享的通道
- ConcurrentSkipListMap:跳表的实现 这是一个Map 使用跳表的数据结构进行快速查找
3.3.2 线程安全的HashMap
让一个线程不安全的HashMap如何变成线程安全的HashMap 一种可行方案就是使用Collections.synchronizedMap()方法包装我们的HashMap
1 | public Map map = Collections.synchronizedMap(new HashMap<>()); |
这个内部实现的方法就是实现一个
1 | public V get(Object key) { |
很明显通过一个mutex作为监听对象的来进行锁 从而实现线程安全
如果并发级别不高 一般也够用 但是 在高并发的环境中 我们也有必要寻求新的解决方案
一个更加专业的并发HashMap是ConcurrentMap 它位于java.util.concurrent包内 它专门为并发进行性能优化 因此 更加适合多线程的场合
3.3.3 有关List的线程安全
队列 链表也是极其常用 几乎所有的应用程序都会与之相关 在Java中 ArrayList与Vector都是使用数组作为其内部实现 俩者最大的不同在于Vector是线程安全的 而ArrayList不是
3.3.4 高效读写的队列:深度剖析ConcurrentLinkedQueue
队列Queue也是常用的数据结构之一 在JDK中提供了一个ConcurrentLinkedQueue类用来实现高并发的队列
ConcurrentLinkedQueue应该算是高并发环境中性能最好的队列就可以了 它之所以有很好的性能 是因为内部复杂的实现
这里需要无锁操作的一些知识
ConcurrentLinkedQueue内部定义结点Node
1 | private static class Node<E> { |
item用来表示目标元素 next字段表示当前Node的下一个元素 这属于数据结构的基础了
对Node进行操作时 使用了CAS操作(CAS是无锁操作相关的知识)
1 | boolean casItem(E cmp, E val) { |
ConcurrentLinkedQueue有俩个重要的字段 head和tail 分别表示链表的头部和尾部 它们都是Node类型 对于head来说 它永远不会为null 并且通过head以及succ()后继方法一定能完整地遍历整个链表 对于tail来说 它自然应该表示队列的末尾
但ConcurrentLinkedQueue的内部实现非常的复杂 它允许在运行多个不同的状态 以tail为例 一般来说 我们期望tail总是为链表的末尾 但实际上 tail的更新并不是及时的 而是可能会产生拖延现象 每次更新会跳跃俩个元素
1 | public boolean offer(E e) { |
能看懂就看懂吧 不懂的话看原书就好 这里写起来字太多 就说些关键的
第二个判断p==q的情况 这种情况是遇到了哨兵结点导致的 所谓哨兵结点 就是next指向自己的结点 这种结点没什么价值 主要表示要删除的结点 或者空结点 当遇到哨兵结点时 无法通过next获得后继元素 就直接返回head 从链表头部开始遍历 但一旦发生在执行过程中 tail被其他线程修改的情况 则进行一次“打赌” 使用新的tail作为链表末尾(这样就避免了重新查找tail的开销)
那么有的人就会对这个语句会不明白了
1 | p = (t != (t = tail)) ? t : head; |
这句代码虽然只有一行 首先!=不是原子操作 它是可以被中断的 也就是说 在执行‘!=’时 程序会先拿t的值 再执行t=tail,并取得新的t的值 然后比较这俩个值是否相等 在单线程中 t!=t这种语句显然不会成立 但是在并发环境中 有可能在获得左边t值后,右边的t值就被其他线程修改 这样t!=t就成立 这里就是这种情况 如果在比较过程中 tail被其他线程修改 当它被再次赋值给t时 就会导致等式左边的t和右边的t不同 如果俩个t不同 表示tail在中断被其他线程篡改 这时 我们就可以用新的tail作为链表末尾 这就是这里等式右边的t 但如果tail没有被修改 则返回head 要求从头部开始 重新查找尾部
下边来看 哨兵结点如何产生的
1 | public E poll() { |
这里写起来又得很麻烦 推荐还是看原书吧 写一些点 这个代码如果看懂之前的offer看这个应该是比较容易了
首先假设加了一个元素在链表中 当前的head的item是null的 使用直接跳到最后p=q 注意在第二个判断中q=p.next 所以这时候p就是p.next了 那么第二次循环item显然不是null的 那么才会去执行p.casItem(item.null)这条语句 成功了就往下走 p当然不等于链表的head了 所以就更新头 而原有的head就被设置为哨兵了
这其实也能感觉到CAS操作设计非常复杂 好处是性能提升 但是难度也是一大跨度
3.3.5 高效读取:不变模式下的CopyOnWriteArrayList
很多应用场景下 读远远大于写 这也是之前的读写锁说的话
为了将读取的性能发挥到极致 JDK中提供了CopyOnWriteArrayList类 对它来说 读取完全不用加锁 并且更好的消息是 写入也不会阻塞读操作 只有写入与写入之间需要同步等待
其实就是在写入操作时 进入一次自我复制 换句话说 当这个List需要修改时 我不修改原有的内容 而是对原有的数据进行一次复制 将修改的内容写入副本中 写完之后 再将修改完的副本替换原来的数据 这样就可以保证写不影响读了
1 | public E get(int index) { |
读取代码没有然后同步控制和所操作 理由就是内部数据array不会发生修改 只会被另外一个array替换因此可以保证数据安全
写入就麻烦了
1 | public boolean add(E e) { |
写入操作用锁 当然这个锁仅限于控制写-写的情况 其重点在于 进行了内部元素的玩转复制 因此 会生成一个新的数组newElements 然后 天魂 而且array是volatile变量 会立即发现
3.3.6 数据共享通道:BlockingQueue
前面提到 是用ConcurrentQueue作为高性能的队列的
并发是追求高性能的 但是多线程的开发模式还会引入一个问题 如何进行多个线程间的数据共享呢
一般来说 我们希望整个系统是松散耦合的
把这个BlockingQueue当做一个‘意见箱’ 双方都放东西 但是双方解耦 保证系统平滑过渡
BlockingQueue是一个接口 主要还是在Blocking上 这个意思就是阻塞
BlockingQueue会让服务线程在队列为空时 进行等待 当有新的消息进入队列后 自动将线程唤醒
我们主要还是用ArrayBlockingQueue这个实现类来说明
向队列中压入元素可以使用offer()和put()方法 对于offer方法 如果当期队列已经满了 它就会返回false 如果没有满 则执行正常的入队操作 所以我们不讨论这个方案 关注put方法 put方法也是将元素压入队列末尾 但如果队列满了 它会一直等待 直到队列中有空闲的位置
从队列中弹出元素可以用poll()方法和take()方法 它们都从队列的头部获得一个元素 不同之处在于 如果队列为空 poll()方法之间返回null,而take()方法会等待 直到队列内有可用元素
因此put方法和take方法才是提醒Blocking的关键 为了做好等待和通知俩件事 在ArrayBlockingQueue定义了如下字段
1 | final ReentrantLock lock; |
当执行take()操作时 如果队列为空 则让当前线程等待在notEmpty上 新元素入队时 则执行一次notEmpty上的通知
1 | public E take() throws InterruptedException { |
这里如果为空就等待 等待新元素的插入 唤醒notEmpty
1 | private void enqueue(E x) { |
同理 对Put()操作也一样 当队列满是 需要让压入线程等待
1 | public void put(E e) throws InterruptedException { |
这里如果为空就等待 等待元素的删除 唤醒notFull
1 | private E dequeue() { |
3.3.7 跳表(SkipList)
跳表是一种可以用来快速查找的数据结构 有点类似于平衡树 它们都可以对元素进行快速的查找 但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整 对跳表的插入和删除只需要对整个数据结构的局部进行操作即可 这样带来的好处是:在高并发的情况下 你会需要一个全局锁来保证整个平衡树的线程安全 而对于跳表 你只需要部分锁即可 这样 在高并发的环境下 你就可以拥有更好的性能 而就查询的性能而言 跳表的时间复杂度也是O(log n) 所以在并发数据结构中 JDK使用跳表来实现一个Map
跳表的另外一个特点是随机算法 跳表的本质是同时维护了多个链表 并且链表是分层的 如下图所示

跳表所有的元素都是排序的 查找时也是如图所示 从顶级链表开始找 一旦发现被查找的元素大于当前链表中的取值 就会转入下一层链表继续找 这也就是说 查找的过程是跳跃式的
因此 很显然 跳表是一种使用空间换时间的算法
使用链表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序 而跳表所有的元素都排序的 因此在对跳表进行遍历时 你会得到一个有序的结果 所以 如果你的应用需要有序性 那么跳表就是你不二的选择
跳表的内部结构有几个关键数据结构组成 一个是Node 一个是Index
Node则就是key value 还有一个next指向下一个Node Index就是索引 内部包装了Node 同时增加了向下引用与向上应用 此外 对于每一层的表头
还需要记录当前处于哪一层 为此 还需要一个称为HeadIndex的数据结构 表示链表头部的第一个Index 它继承于Inndex
第四章 锁的优化及注意事项
4.1 有助于提高“锁”性能的几点建议
4.1.1 减少锁持有时间
程序开发应尽可能的减少对某个锁的占用时间 以减少程序互斥的可能
1 | public synchronized void syncMethod(){ |
这里假设只有mutextMethod方法是有同步需要的 而othercode1()和othercode2()并不需要同步控制 如果othercode1和othercode2是重量级的方法的话 使用整个个方法做同步 会导致等待线程大量增加 因为一个线程 在进入该方法时获得内部锁 只有在所有任务都执行完后 才会释放锁
一个较为优化的解决方案是 只在必要时进行同步 这样就能明显减少线程持有锁的时间 提高系统的吞吐量
1 | public void syncMethod2(){ |
在改进的代码中 只针对mutextMethod()方法做了同步 锁占用的时间相对较短 因此能有更改的并行度 这种技术手段在JDK的源码包中也可以很容易地找到 比如处理正则表达式的Pattern类
减小锁的持有时间有助于减低锁冲突的可能性 进而提高系统的并发能力
4.1.2 减小锁粒度
减小锁粒度也是削弱多线程锁竞争的有效手段 这种技术典型的使用场景就是ConcurrentHashMap类的实现 在3.3节中介绍了这个类 但是没有仔细的介绍 这节仔细的介绍一下
对于HashMap来说 最重要的俩个方法就是get()和put()。一种最自然的方法就是对HashMap加锁 必然可以得到一个线程安全的对象 但是这样做 我们就认为加锁粒度太大了 对于ConcurrentHashMap 它内部进一步细分为若干个小的HashMap 称之为段(SEGMENT) 默认情况下 一个ConcurrentHashMap被进一步细分为16个段
如果需要在ConcurrentHashMap中增加一个新的表项 并不是将整个HashMap加锁 而是首先根据hashcode得到该表现应该存放到哪个段中 然后对该段加锁 并完成put()操作 只要被加入的表项不存放在同一个段中 则线程间便可以做到真正的并行
但是 减小锁粒度会引入一个新的问题 即:当系统需要取得全局锁时 其消耗的资源会比较多 仍然以ConcurrentHashMap类为例 虽然其put()方法很好地分离了锁 但是当试图访问ConcurrentHashMap全局信息时 就会需要同时取得所有段的锁方能顺利实施 比如ConcurrentHashMap的size()方法 它将返回ConcurrentHashMap的有效表项的数量 即ConcurrentHashMap的全部有效表项之和 要获取这个信息需要取得所有子段的锁
事实上 size()方法会先使用无锁的方式求和 如果失败才会尝试加锁的方法 但不管怎么说 在高并发场合ConcurrentHashMap的size()的性能依然要差于同步的HashMap
因此 只有在类似size()获取全局信息的方法调用并不频繁时 这种减小锁粒度的方法才能真正意义上提高系统吞吐量
ConcurrentHashMap在JDK1.8版本中大规模的重构了 这里的笔记只适用于JDK1.7版本
所谓减少锁粒度 就是指减少锁定对象的访问 从而减少锁冲突的可能性 进而提高系统的并发能力
4.1.3 读写分离锁来替换独占锁
使用ReadWriteLock可以提高系统的性能 使用读写分离锁来替代独占锁是减小锁粒度的一种特殊情况 那么 读写锁则是对系统功能点的分割
在读多写少的场合 读写锁对系统性能还是很有好处的 因为如果系统在读写数据时均只使用独占锁 那么读操作和写操作间 写操作和写操作间均不能做到真正的并发 并且需要互相等待 而读操作本身不会影响数据的完整性和一致性 因此 理论上讲 在大部分情况下 应该可以运行多线程同时读,读写锁正是实现了这种功能
在读多写少的场合 使用读写锁可以有效提示系统的并发能力
4.1.4 锁分离
如果将读写锁的思想做进一步的延伸 就是锁分离 读写锁根据读写操作功能的不同进行了有效的锁分离 依据应用程序的功能特点 使用类似的分离思想 也可以对独占锁进行分离 一个典型的案例就是java.util.LinkedBlockingQueue的实现
在LinkedBlockingQueue的实现中 take()函数和put()函数分别实现了从队列中取得数据和往队列中增加数据的功能 虽然俩个函数都对当前队列进行了修改操作 但由于LinkedBlockingQueue是基于链表的 因此 俩个操作分别作用域队列的前端和尾端 从理论上说 俩者并不冲突
如果使用独占锁 则要求俩个操作进行时获取当前队列的独占锁 那么take()和put()操作就不可能真正的并发 在运行时 它们会彼此等待对方释放锁资源 在这种情况下 锁竞争会相对比较激烈 从而影响程序在高并发时的性能
因此 在JDK的实现中 并没有采用这样的方式 取而代之的是俩把不同的锁 分离了take()和put()操作
1 | /** Lock held by take, poll, etc */ |
以上代码片段 定义了takeLock和putLock 它们分别在take()操作和put()操作中使用 因此 take()函数和put()函数就此相互独立 它们之间不存在锁竞争关系 只需要在take()和take()间,put()和put()间分别对takeLock和putLock进行竞争 从而 削弱了锁竞争的可能性
1 | public E take() throws InterruptedException { |
函数put()的实现如下
1 | public void put(E e) throws InterruptedException { |
通过takeLock和putLock俩把锁 LinkedBlockingQueue实现了取数据和写数据的分离 使俩者在真正意义上成为可并发的操作
4.1.5 锁粗化
通常情况下 为了保证多线程间的有效并发 会要求每个线程持有锁的时间尽量短 即在使用完公共资源后 应该立即释放锁 只有这样 等待在这个锁上的其他线程才能尽早的获得资源执行任务 但是 如果对同一个锁不停的进行请求,同步和释放 其本身也会消耗系统宝贵的资源 反而不利于性能的优化
为此 虚拟机在遇到一连串连续对同一锁不断进行请求和释放的操作时,便会把所有的锁操作整合成对锁的一次请求 从而减少对锁的请求同步次数 这个操作叫锁的粗化
1 | public void demoMethod(){ |
会被整合为如下形式
1 | public void demoMethod(){ |
在开发过程中 大家也应该有意识地在合理的场合进行锁的粗化 尤其当在循环内请求锁时 以下是一个循环内请求锁的例子 在这种情况下 意味着每次循环都有申请锁和释放锁的操作 但在这种情况下 显然是没有必要的
1 | for(int i =0;i<CIRCLE;i++){ |
所以 一种更合理的做法应该是在外层只请求一次锁
1 | synchronized(lock){ |
注意 性能优化是根据运行时的真是情况对各个资源点进行权衡折中的过程 锁粗化的思想和减少锁持有时间是相反的 但在不同的场合 它们的效果并不相同 所以大家需要根据实际情况 进行权衡
4.2 Java虚拟机对锁优化所做的努力
4.2.1 锁偏向
锁偏向是一种针对加锁操作的优化手段 它的核心思想是:如果一个线程获得了锁 那么锁就进入了偏向模式 当这个线程再次请求锁时 无须再做任何同步操作 这样就节省了大量相关锁申请的操作 从而提高了程序性能 因此 对于几乎没有锁竞争的场合 偏向锁有比较好的优化效果 因为连续多次极有可能是同一个线程请求相同的锁 而对于锁竞争比较激烈的场合 其效果不佳 因为在竞争激烈的场合 最有可能的情况是每次都是不同的线程来请求相同的锁 这样偏向模式会失效 因此还不如不启用偏向锁 使用Java虚拟机参数-XX:+UseBiasedLocking可以开启偏向锁
4.2.2 轻量级锁
如果偏向锁失败 虚拟机并不会立即挂起线程 它还会使用一种称之为轻量级锁的优化手段,轻量级锁的操作也很轻便 它只是简单的将对象头部作为指针 指向持有锁的线程堆栈的内部 来判断一个线程是否持有对象锁 如果线程获得轻量级锁成功 则可以顺利进入临界区 如果轻量级锁加锁失败 则表示其他线程抢先争夺到了锁 那么当前线程的锁请求就会膨胀为重量级锁
4.2.3 自旋锁
锁膨胀后,虚拟机为了避免线程真实地在操作系统层面挂起 虚拟机还会在做最后的努力
—自旋锁 由于当前线程暂时无法获得锁 但是什么时候可以获得锁是一个未知数
也许在几个CPU时钟周期后 就可以得到锁 如果这样 简单粗暴地挂起线程可能是一种得不偿失的操作 因此 系统会进行一次赌注:它会加上在不久的将来 线程可以得到这把锁 因此 虚拟机会让当前线程做几个空循环(这也是自旋的含义)在经过若干次循环后 如果可以得到锁 那么就顺利进入临界区 如果还不能获得锁 才会真实地将线程在操作系统层面挂起
4.2.4 锁消除
锁消除是一种更彻底的锁优化 Java虚拟机在JIT编译时 通过对运行上下文的扫描 去除不可能存在共享资源竞争的锁 通过锁消除 可以节省毫无意义的请求锁时间
如果不可能存在竞争 为什么程序还要加上锁呢 这是因为在Java软件开发的过程中 我们必然会使用一些JDK的内置API,比如StringBuffer,Vector等 你在使用这些类的时候 也许根本不会考虑这些对象到底内部是如何实现的 比如 你很有可能在一个不可能存在并发竞争的场合使用Vector 而众所周知 Vector内部使用了synchronized请求锁
1 | public String[] createStrings(){ |
比如在这种情况下 Vector的实例对象v只是一个局部变量 局部变量是在栈上的 属于线程私有的数据 因此不可能被其他线程访问 所以 在这种情况下 Vector内部所有加锁同步都是没有必要的 如果虚拟机检测到这种情况 就会将这些无用的操作去除
锁消除涉及的一项关键技术为逃逸分析 所谓逃逸分析就是观察某一个变量是否会逃出某一个作用域
在本例中 变量v显然没有逃出createStrings()函数之外 以此为基础 虚拟机才可以大胆地将v内部的加锁操作去除 如果createStrings()返回的不是String数组 而是v本身 那么就认为变量v逃逸出了当前函数 也就是说v有可能被其他线程访问 如果是这样 虚拟机就不能消除v中的锁操作
逃逸分析必须要在-server模型下进行 可以使用-XX:DoEscapeAnalysis参数打开逃逸分析 使用-XX:+EliminateLocks参数可以打开锁消除
4.3 人手一只笔:ThreadLocal
除了控制资源的访问外 我们还可以通过增加资源来保证所有对象的线程安全
4.3.1 ThreadLocal的简单实用
从ThreadLocal的名字上可以看到 这是一个线程的局部变量 也就是说只有当前线程可以访问 既然是只有当前线程可以访问的数据 自然是线程安全的
下面看一个简单的示例
相关代码请见 ThreadLocalDemo
从这里也可以看到 为每一个线程人手分配一个对象的工作并不是由ThreadLocal来完成的 而是需要在应用层面保证的 如果在应用上为每一个线程分配了相同的对象实例 那么ThreadLocal也不能保证线程安全 这点也需要大家注意
注意:为每一个线程分配不同的对象 需要在应用层面保证 ThreadLocal只是起到了简单的容器作用
4.3.2 ThreadLocal的实现原理
我们需要关注的 自然是ThreadLocal的set()方法和get()方法 从set()方法说起
1 | public void set(T value) { |
可以看到这个方法set时 先获得当前线程对象 然后通过getMap()拿到线程的ThreadLocalMap,并将值设入ThreadLocalMap 而ThreadLocalMap就理解为一个Map就好 但是它是定义在Thread内部的成员
1 | ThreadLocal.ThreadlocalMap threadLocals =null; |
而设置到ThreadLocal中的数据 也正是写入了threadLocals这个Map 其中 key为ThreadLocal当前对象 value就是我们需要的值 而threadLocals本身就保存了当前所在线程的所有“局部变量”,也就是一个ThreadLocal变量的集合
在进行get()操作时 自然就是将这个Map中的数据拿出来
1 | public T get() { |
因此 如果我们使用线程池 那就意味着当前线程未必会退出(比如固定大小的线程池,线程总是存在) 如果这样 将一些大大的对象设置到ThreadLocal中(它实际保存在线程持有的ThreadLocal Map内) 可能会使系统出现内存泄露的可能(这里的意思是:你设置对象到ThreadLocal中 但是不清理它 在你使用几次后 这个对象也不再有用了 但是它却无法被回收)
此时 如果你希望及时回收对象 最好使用ThreadLocal.remove()方法将这个变量移出 就像我们有时候为了加速垃圾回收 会特意写出类似obj=null的代码 如果这么做 obj指向的对象就会更容易的被垃圾回收器发现 从而加速垃圾回收
同理 如果对于ThreadLocal的变量 我们也手动将其设置为null 比如tl=null 那么这个ThreadLocal对于的所有线程的局部变量都有可能被回收
相关代码请见 ThreadLocalDemo_GC
要了解这里的回收机制 我们需要更进一步了解ThreadLocal.ThreadLocalMap的实现 ThreadLocalMap是一个类似WeakHashMap的东西
ThreadLocalMap的实现使用了弱引用 弱引用是比强引用弱的多的引用 Java虚拟机在垃圾回收时 如果发现弱引用 就立即回收 ThreadLocalMap内部是由一系列Entry构成 每一个Entry都是WeakReference
1 | static class Entry extends WeakReference<ThreadLocal<?>> { |
这里的参数k就是Map的key v就是Map的value 其中k也就是ThreadLocal实例 作为弱引用使用(super(k)就是调用了WeakReference的构造函数) 因此 虽然这里使用ThreadLocal作为Map的key 但是实际上 它并不真的持有ThreadLocal的引用 而当ThreadLocal的外部强引用被回收时 ThreadLocalMap中的key就变为null 当系统进行ThreadLocalMap清理时(比如将新的变量加入表 就会自动进行一次清理 虽然JDK不一定会进行一次彻底的扫描但显然在我们这个案例中 它奏效了) 就会自然将这些垃圾数据回收
4.3.3 对性能有何帮助
为每一个线程分配一个独立的对象对系统性能也许是有帮助的 当然 这也不一定 这完全取决于共享对象的内部逻辑 如果共享对象对于竞争的处理容易引起性能损失
我们还是应该考虑使用ThreadLocal为每个线程分配单独的对象 一个典型的案例就是在多线程下使用随机数
相关代码请见 RandomThreadLocalTest
4.4 无锁
人是分为乐天派与悲观派的 那么对并发控制的处理也是分为乐观与悲观的
锁就是一种悲观的策略 它总是假设每一次的临界区操作会产生冲突,因此,必须对每次操作都小心翼翼 如果有多个线程同时需要访问临界区资源 就宁可牺牲性能让线程进行等待 所以说锁会阻塞线程执行
而无锁是一种乐观的策略 它总是假设对资源的访问是没有冲突的 既然没有冲突 自然不需要等待 所以所有的线程都可以在不停顿的状态下持续执行 那遇到冲突怎么办?无锁的策略使用一种叫比较交换的技术(CAS CompareAndSwap)来鉴别线程冲突 一旦检测到冲突产生 就重试当前操作直到没有冲突为止
4.4.1 与众不同的并发策略:比较交换(CAS)
与锁相比 使用比较交换 简称为CAS会使程序看起来复杂一些 但由于其非阻塞性 它对死锁问题天生免疫 并且 线程间的相互影响也远远比基于锁的方式要小 更为重要的是 使用无锁的方式完全没有锁竞争代理的系统开销 也没有线程间频繁调度带来的开销 因此 它要比基于锁的方式拥有更优越的性能
CAS算法的过程是这样的:它包含3个参数CAS(V,E,N),V表示要更新的变量 E表示预期值 N表示新值 仅当V值等于E值时 才会将V的值更新为N 如果V值和E值不同 则说明已经有其他线程做了更新 则当前线程什么都不做 最后 CAS返回当前V的真实值 CAS操作是抱着乐观的态度进行的 它总是认为自己可以独立完成操作
当多个线程同时使用CAS操作一个变量时 只有一个会胜出 并成功更新 其他均会失败 失败的线程不会被挂起 仅是被告知失败 并且允许再次尝试 当然也允许失败的线程放弃操作 基于这样的原理 CAS操作即使没有锁 也可以发现其他线程对当前线程的干扰 并进行恰当的处理
简单的说,CAS需要你额外给出一个期望值 也就是你认为这个变量现在应该是什么样子的 如果变量不是你想象的那样 那说明它已经被别人修改过了 你就重新读取 再次尝试修改就好了
在硬件层面 大部分的现代处理器都已经支持原子化的CAS指令 在JDK5.0以后 虚拟机便可以使用这个指令来实现并发操作和并发数据结构 并且 这种操作在虚拟机中可以说是无处不在
4.4.2 无锁的线程安全整数 AtomicInteger
为了让Java程序员能够受益于CAS等CPU指令 JDK并发包中有一个atomic包 里面实现了一些直接使用CAS操作的线程安全类型
其中 最常用的一个类 应该就是AtomicInteger 你可以把它看做是一个整数 但是与Integer不同 它是可变的 并且是线程安全的 对其进行修改等任何操作 都是用CAS指令进行的 这里简单列举一些AtomicInteger的一些主要方法 对于其他原子类 操作也是非常相似的
1 | public final int get()//取得当前值 |
就内部实现上来说 AtomicInteger中保存了一个核心字段
1 | private volatile int value; |
它代表了AtomicInteger的当前实际值 此外还有一个
1 | pirvate static final long valueObject; |
它保存了value字段在AtomicInteger对象中的偏移量 后面你会看到 这个偏移量是实现AtomicInteger的关键
下面的代码是AtomicInteger的使用示例
相关代码请见 AtomicIntegerDemo
使用AtomicInteger会比使用锁有更好的性能 这里就不进行测试了
和AtomicInteger类似的类还有AtomicLong用来代码long类型 AtomicBoolean表示boolean型 AtomicReference表示对象引用
4.4.3 Java中的指针:Unsafe类
1 | public final boolean compareAndSet(int expect, int update) { |
在这里,我们看到了一个特殊的变量unsafe 它是sun.misc.Unsafe类型 从名字看 这个类应该是封装了一些不安全的操作 那什么操作是不安全的呢 学习过C或者c++都知道 指针是不安全的 这也是在Java中把指针去除的重要原因 如果指针指错了位置或者计算指针偏移量出错 结果可能是灾难性的 你很有可能覆盖别人的内存 导致系统崩溃
而这里的Unsafe就是封装了一些类似指针的操作 compareAndSwapInt()方法是一个natvie 方法 它的几个参数含义如下
1 | public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x); |
第一个参数o为给定的对象 offset为对象内的偏移量(其实就是一个字段到对象头部的偏移量 通过这个偏移量可以快速定位字段),expected表示期望值 x表示要设置的值 如果指定的字段的值等于expected 那么就会把它设置为x
不难看出,compareAndSwapInt()方法的内部 比如是使用CAS原子指令完成的 此外 Unsafe类还提供了一些方法
1 | //获得给定对象偏移量上的int值 |
在之前的3.3.4 深度剖析ConcurrentLinkedQueue一节中描述的ConcurrentLinkedQueue实现 应该对ConcurrentLinkedQueue中的Node还有些印像 Node的有一些CAS操作也是使用Unsafe类来是实现的
这里就可以看到 虽然Java派遣了指针 但是在关键时刻 类似指针的技术还是必不可少的 这里底层的Unsafe实现就是最好的例子 但是很不幸 JDK的开发人员不希望大家使用这个类 获得Unsafe实例的方法就是调动其工厂方法getUnsafe(),但是他的实现却是这样的
1 | public static Unsafe getUnsafe() { |
注意 这里的代码如果是ClassLoader不为null 就会抛出异常 拒绝工作 因此 这也使得我们自己的应用程序无法直接使用Unsafe类 它是一个JDK内部使用的专属类
注意:根据Java类加载器的工作原理 应用程序的类由AppLoader加载 而系统核心类 如rt.jar中的类由Bootstrap类加载器加载 Bootstrap加载器没有Java对象的对象 因此试图获得这个类加载器会返回null 所以 当一个类的类加载器为null时 说明它是Bootstrap加载的 而这个类极有可能是rt.jra中的类
4.4.4 无锁的对象引用:AtomicReference
AtomicReference和AtomicInteger非常类似 不同之处就在与AtomicInteger是对整数的封装 而AtomicReference则对应普通的对象引用
也就是它可以保证你在修改对象引用是的线程安全性
之前说过 线程判断被修改对象是否可以正确写入的条件是对象的当前值和期望值是否一致 这个逻辑从一般意义上是对的 但是有一个小小的意外 这个就是ABA问题 当你获得对象当前数据后 在准备修改为新值前 对象的值被其他线程连续修改了俩次 而经过这俩次修改后 对象的值又恢复为旧值 这样 当前线程就无法正确判断这个对象究竟是否被修改过
一般来说 发生这种情况的概率很小 而且即使发生了 可能也不是什么大问题 比如 我们只是很简单地做一个数值加法 即使我在取得期望值后 这个数字被不断的修改 只要它最终改回了我的期望值 我的加法计算就不会出错 也就是说 当你修改个对象没有过程的状态信息 所有的信息都只保存与对象的数值本身
但是 在现实中 还可能存在另外一种场景 就是我们是否能修改对象的值 不仅取决于当前值 还和对象的过程变化有关 这时 AtomicRenference就无能无力了
举个例子 如果有一家点 为了挽留客户 决定为贵宾卡余额小于20元的客户一次性赠送20元 刺激消费者充值与消费
但条件时 每个客户只能被赠送一次
使用AtomicReference演示这个场景
相关代码请见 AtomicReferenceDemo
这里就会出现一个问题 用户正好在进行消费 就在赠予金额的同时 他进行了一次消费 使得总金额又小于20元 并且正好累计消费了20元 使得消费,赠予后的金额等于消费前,赠予前的金额 这时 后台的赠予进程就会误以为这个账户还没有赠予 所以 存在被多次赠予的可能
1 | 余额小于20元 充值成功,余额:39元 |
从输出中可以看到 这个账号先后被反复充值 其原因正是因为账号余额被反复修改 修改后的值等于原有的值 使得CAS操作无法正确判断当前数据状态
虽然说这种情况出现的概率不大 但是依然是有可能出现的 因此 当业务确实可能出现这种情况时 我们也必须多加防范 体贴的JDK也已经为我们考虑到了这种情况 使用AtomicStampedReference就可以很好地解决这个问题
4.4.5 带有时间戳的对象引用:AtomicStampedReference
AtomicReference无法解决上述问题的根本是因为对象在修改的过程中 丢失了状态信息 对象值本身与状态被画上了等号 因此 我们只要能记录对象在修改过程中的状态值 就可以很好的解决对象被反复修改导致线程无法正确判断对象状态的问题
AtomicStampedReference就是这么做的 它内部不仅维护对象值 还维护了一个时间戳(我这里把它称之为时间戳,实际上它可以使任何一个整数来表示状态值) 当AtomicStampedReference对应的数值被修改时 除了更新数据本身外 还必须要更新时间戳 当AtomicStampedReference设置新对象时 对象值以及时间戳必须满足期望值 写入才会成功 因此 即使对象值被反复读写 写回原值 只有时间戳发生变化 就能防止不恰当的写入
AtomicStampedReference的几个API在AtomicReference的基础上新增了有关时间戳的信息
1 | //比较设置 参数以此为:期望值 写入新值 期望时间戳 新时间戳 |
有了AtomicStampedReference这个法宝 我们就再也不用担心对象被写坏
使用AtomicStampedReference来修正AtomicReferenceDemo的问题
相关代码请见 AtomicStampedReferenceDemo
我们使用AtomicStampedReference代替原来的AtomicReference 首先获得账户的时间戳 后续的赠予操作以这个时间戳为依据 如果赠予成功 则修改时间戳 使得系统不可能发生二次赠予的情况 消费线程也是类似 每次操作 都使得时间戳加1 使之不可能重复
4.4.6 数组也能无锁:AtomicIntegerArray
除了提供基本数据类型外 JDK还为我们提供了数组等复合结构 当前可用的原子数组有:AtomicIntegerArray,AtomicLongArray和AtomicReferenceArray,分别表示整数数组 long类型数组和普通的对象数组
AtomicIntegerArray本质上是对int[]类型的封装 使用Unsafe类通过CAS的方式控制int[]在多线程下的安全性 它提供了以下几个核心API
1 | //获得数组第i个下标的元素 |
相关代码请见 AtomicIntegerArrayDemo
4.4.7 让普通变量也享受原子操作:AtomicIntegerFieldUpdater
有时候,由于初期考虑不周 或者后期的需求变化 一些普通变量可能也会有线程安全的需求 如果改动不大 我们可以简单地修改程序中的每一个使用或者读取这个变量的地方 但显然,这样不符合软件设计中的一条重要原则 —开闭原则 也就是系统对功能的增加应该是开发的 而对修改应该是相对保守的
所以在原子包里还有一个实用的工具类AtomicIntegerFieldUpdater 它可以让你不改动原有代码的基础上 让普通的变量也享受CAS操作带来的线程安全性 这样你可以修改极少的代码,来获得线程安全的保证
根据数据类型的不同 这个Updater有三种 分别是AtomicIntegerFieldUpdater,AtomicLongFieldUpdater和AtomicReferenceFieldUpdater 顾名思义 它们分别可以对int,long和普通对象进行CAS修改
相关代码请见 AtomicIntegerFieldUpdaterDemo
虽然AtomicIntegerField很好用 但是还有几个注意事项:
- 第一 Updater只能修改它可见访问内的变量 因为Updater使用反射 如果变量不可见 就会出错 比如如果score申明为private 就是不可行的
- 第二 为了确保变量被正确的读取 它必须是volatile类型的 如果我们原有代码中未申明这个类型 那么简单地申明一下就行 这不会引起什么问题
- 第三 由于CAS操作会通过对象实例中的偏移量直接进行赋值 因此 它不支持static字段(Unsafe.objectFieldOffset()不支持静态变量)
4.4.8 挑战无锁算法:无锁的Vector实现
这段讲我很迷 以后再补吧 这里讲的是 Amino CBB 实现的LockFreeVector 我不知道作者在这里主要讲Vector的扩容机制的目的是什么 可能是因为get与push_back俩个方法是最关键的俩个方法把 有兴趣的自己翻书吧
4.4.9 让线程之间互相帮助:细看SynchronousQueue的实现
在对线程池的介绍中 提到了一个非常特殊的等待队列SynchronousQueue
SynchronousQueue的容量为0
任何一个对SynchronousQueue的写需要等待一个SynchronousQueue的读 反之亦然 因此 SynchronousQueue与其说是一个队列 不如说是一个数据交换通道
SynchronousQueue中有大量的无锁操作
对SynchronousQueue来说 它将put()和take()俩个功能截然不同的操作抽象为一个共同的方法Transferer.transfer() 从字面上看 它就是数据传递的意思
它的完整签名如下
1 | E transfer(E e, boolean timed, long nanos) |
当参数e未非空时 表示当前操作传递给一个消费者 如果为空 则表示当前操作需要请求一个数据 timed参数决定是否存在timeout时间 nanos决定了timeout的时长 如果返回值为非空 则表示数据已经接受或者正常提供 如果为空 则表示失败(超时或者失败)
SynchronousQueue内部会维护一个线程等待队列
Trasferer.transfer()函数的实现是SynchronousQueue的核心 它大体分为三个步骤
- 如果等待队列为空 或者队列中的节点的类型和本次操作是一致的 那么将当前操作压入队列等待 比如等待队列中是读线程等待 本次操作也是读 因此这俩个读都需要等待 进入等待队列的线程可能会被挂起 它们会等待一个‘匹配’操作
- 如果等待队列中的元素和本次操作互补(比如等待操作是读,而本次操作是写) 那么就可以插入一个‘完成’状态节点 并且让他‘匹配’到一个等待节点上 接着弹出这俩个节点 并且使得对于的俩个线程继续执行
- 如果线程发现等待队列的节点就是‘完成’节点 那么帮助这个节点完成任务 其流程和步骤2是一致的
步骤一的实现如下 代码参考JDK 1.8.0_141
1 | SNode h = head; |
第一行SNode表示等待队列的节点 内部封装了当前线程,next节点,匹配节点,数据内容等信息 第二行 判断当前等待队列为空 或者队列中的元素的模式与本次操作相同 第8行 生成一个新的节点并置于队列头部 这个节点就代表当前线程 如果入队成功 则执行第9行的awaitFulfill()函数,该函数被唤醒后(表示已经读取到数据或者自己尝试的数据已经被别的线程读取)在14-15行尝试帮助对应的线程完成俩个头部节点的出队操作(仅仅是友情帮助) 并在最后 返回读取或者写入的数据
步骤二的实现如下
1 | } else if (!isFulfilling(h.mode)) { // 是否处于fulfill状态 |
首先判断头部节点是否处于Fulfill模式 如果是 进入步骤三 否则 就视自己为对应的fulfill线程 第4行 生成一个SNode节点 设置为fulfill模式并将其压入队列头部 接着 设置m(原始的队列头部)为s的匹配节点 这个tryMatch()操作将会激活一个等待线程 并将m传递给那个线程 如果设置成功 则表示数据投递完成 将s和m俩个节点弹出即可 如果tryMatch()失败 则表示已经有其他线程帮我完成了操作 那么简单得删除m节点即可 因为这个节点已经被投递 不需要再次处理 然后 再次跳转到第5行的循环体 进行下一个等待线程的匹配和数据投递 直到队列中没有等待线程为止
1 | } else { // 帮助一个fulfiller |
上述代码的执行原理与步骤2是完全一致的 唯一的不同是步骤3不会返回 因为步骤3进行工作是帮助其他线程尽快投递它们的数据 而自己并没有完成对应的操作 因此 线程进入步骤3后 再次进入大循环体 才能步骤1开始重新判断和投递数据
从整个数据投递的过程中可以看到 在SynchronousQueue中 参与工作的所有线程不仅仅是竞争资源的关系 更重要的是 它们彼此之间还会互相帮助 在一个线程内部 可能会帮助其他线程完成它们的工作 这种模式可以更大程度上减少饥饿的可能 提供系统整体的并行度
4.5 有关死锁的问题
在一般情况下 使用锁的情况一般比无锁要多 而且在复杂的业务系统中 使用无锁的难度也是非常的高 但是使用锁 就会引起一个问题 –那就是死锁
什么是死锁 死锁就是俩个或者多个线程 相互占用对方需要的资源 而都不进行释放 导致彼此之间都相互等待对方释放资源 产生了无限制等待的现象 死锁一旦发生 如果没有外力介入 这种等待将永远存在 从而对程序的产生严重的影响
用来描述死锁问题的一个有名场景就是‘哲学家就餐’问题
假设有五位哲学家围坐在一张圆形餐桌旁,做以下两件事情之一:吃饭,或者思考。吃东西的时候,他们就停止思考,思考的时候也停止吃东西。餐桌中间有一大碗意大利面,每两个哲学家之间有一只餐叉。因为用一只餐叉很难吃到意大利面,所以假设哲学家必须用两只餐叉吃东西。他们只能使用自己左右手边的那两只餐叉。哲学家就餐问题有时也用米饭和筷子而不是意大利面和餐叉来描述,因为很明显,吃米饭必须用两根筷子。
哲学家从来不交谈,这就很危险,可能产生死锁,每个哲学家都拿着左手的餐叉,永远都在等右边的餐叉(或者相反)。
如图
假设最简单的情况 就是只有2个哲学家 A和B A左手拿着其中一只叉子 B也一样 这样他们的右手都在等待对方的叉子 并且这种等待会继续 从而导致线程无法运转
下面用一个简单的例子模拟这个过程
相关代码请见 DeadLock
如果在实际环境中 遇到了这种情况 通常的表现就是相关的进程不再工作 并且CPU占用率为0(因为死锁的显存不占用CPU),不过这种表现线性只能猜测问题 如果想要确认问题 还需要使用JDK提供的一套专业工具
我们可以使用jps命令得到java进程的ID 接着使用jstack命令得到线程的线程堆栈
想要避免死锁 除了使用无锁的函数外 另外一种有效的方法就是使用第三章介绍的重入锁 通过重入锁的中断或者限时等待可以有效避免死锁代理的问题
相关代码请见 DeadLockInterruptSolve
相关代码请见 DeadLockTimeLockSolve
第5章 并行模式与算法
5.1 探讨单例模式
单例模式是一个对象创建模式 用于产生一个对象的具体实例 它可以确保系统中一个类只产生一个实例 在Java中 这样的行为能带来俩大好处
- 对于频繁使用的对象 可以省略new操作花费的时间 这对于那些重量级对象而言 是非常可观的一笔系统开销
- 由于new操作的次数减少 因而对系统内存的使用频率也会降低 这将减轻GC压力 缩短GC停顿时间
严格来说 单例模式与并行没有直接的关系
下面是一个单例的实现
1 | public class Singleton{ |
要保证系统中不会有人意外创建多余的实例 因此 我们把Sington的构造函数设置为private 这点非常重要 这就警告所有的开发人员 不能随便创建这个类的实例 从而有效避免该类被错误的创建
第二点 instance对象必须是private并且static的 如果不是privat 那么instance的安全性无法得到保证 一个小小的以外就可能使得instance变成null 其次 因为工程方法getInstance()必须是static的 因此对于的instnace也必须是static
但是这种方式有一点不足 就是Singleton构造函数 或者说Sington实例在什么时候创建是不受控制的 对于静态成员instance 它会在类第一次初始化的时候被创建 这个时刻并不一定是getInstance()方法第一次被调用的时候
比如
1 | public class Singleton{ |
注意 这个单例还包含一个表示状态的静态成员STATUS 此时 在相同任何地方应用这个STATUS都会导致instance实例被创建(任何对Singleton方法或者字段的引用 都会导致类初始化 并创建intance实例 但是类初始化只有一次 因此instance实例永远只会被创建一次)
比如
1 | System.out.println(Singleton.STATUS); |
上述println会打印出
1 | Singleton is create |
可以看到 即使系统没有要求创建单例 new Singleton()也会被调用
如果你想精准控制instance的创建时间 那么这种方法就不太友善了
有一种新的方法 一种支持延迟加载的策略 它慧慧在instance背第一次使用时 创建对象 具体实现如下
相关代码请见 LazySingleton.java
LazySingleton的核心思想如下 最初 并不需要实例化instance 而当getInstance()方法被第一次调用时 创建单例对象 为了防止对象被多次创建 我们不得不需使用synchronized进行方法同步 这种实现的好处是充分利用了延迟加载 只在真正需要时创建对象 但坏处也很明显并发加锁竞争激烈的场合对性能会产生一定的影响
此外 还有一种被称为双重检测模式的方法可以用于创建单例 这里不打算介绍 这是一种不好又复杂的方法 甚至在低JDK中不能保证正确性
有一种方法可以结合二者之优势
相关代码请见StaitcSingleton.java
以上代码实现了一个单例 并且同时拥有前俩种方法的优点 首先getInstance()方法中没有锁 这使得在高并发环境下性能卓越 其次 只有在getInstance()方法被第一次调用时 StaticSingleton的实例才会被创建 因为这种方法巧妙地使用了内部类和类的初始化方式 内部类SingletonHolder被申明为private 这使得我们不可能在外部访问并初始化它 而我们值可能在getInstance()内部对SingletonHolder类进行初始化 利用虚拟机的类初始化机制创建单例
5.2 不变模式
多线程对同一个对象进行读写操作时 为了保证对象数据的一致性和正确性 有必要对对象进行同步 而同步操作对系统性能是有相当的损耗的 可以使用一种不会改变的对象 依靠对象的不变形 可以确保其在没有同步操作时的多线程环境中依然始终保持内部状态的一致性和正确性 这就是不变模式
不变模式天生就是多线程友好的 它的核心思想是 一旦一个对象被创建 则它的内部状态永远不会发生改变 所以 没有一个线程可以修改其内部状态和数据 同时其内部状态也绝不会自行发生改变 基于这些特性 对不变对象的多线程操作不需要进行同步控制
同时还需要注意 不变对象和只读属性是有一定的区别的 不变模式是比只读属性具有更强的一致性和不变形 对只读属性的对象而言 对象本身不能被其他线程修改 但是对象的自身状态却可能自行修改
因此 不变模式的主要使用场景需要满足以下2个条件:
- 当对象被创建后 其内部状态和数据不再发生任何变化
- 对象需要被共享 被多线程频繁访问
在Javayuy中 不变模式的实现很简单 为确保对象被创建后 不发生任何改变 并保证不变模式正常工作 只需要注意以下4点
- 去除setter方法以及所有修改自身属性的方法
- 将所有属性设置为私有 并用final标记 确保其不可修改
- 确保没有子类可以重载它的行为
- 有一个可以创建完整对象的构造函数
下面代码实现了一个不变的产品对象 它拥有序列号 名称 和价格三个属性
在JDK中 不变模式用的非常广泛 其中 最为典型的就是java.lang.String类 此外 所有元数据包装类 都是使用不变模式实现的
由于基本数据类型和String类型在实际的软件开发中应用极其广泛 使用不变模式 所有实例的方法都不需要同步操作 保证了多线程下的性能
不变模式通过回避问题而不是解决问题的态度来处理多线程并发访问控制
5.3 生产者-消费者模式
生产者-消费者模式是一个经典的多线程设计模式 它为多线程间的协作提供了良好的解决方案 在生产者-消费者模式中 通常有两类线程 即若干个生产者线程和若干个消费者线程 生成者线程负责提交用户请求 消费者线程则负责处理生产者提交的任务 生产者和消费者之间通过共享内存缓冲区来进行通信
生产者-消费者模式中的内存缓存区的主要功能是数据在多线程间的共享 此外 通过该缓冲区 可以缓解生成者和消费者之间的性能差
生产者-消费者模式的核心组件是共享内存缓冲区 它作为生产者和消费者间的通信桥梁
| 角色 | 作用 |
|---|---|
| 生产者 | 用于提交用户请求 提取用户任务 并装入内存缓冲区 |
| 消费者 | 在内存缓冲区中提取并处理任务 |
| 内存缓冲区 | 缓冲生产者提交的任务或数据 供消费者使用 |
其中 BlockingQueue充当了共享内存缓冲区 用于维护任务或数据队列

BlockingQueue在第三章
相关代码请见BlcokingQueue
5.4 高性能的生产者-消费者:无锁的实现
BlockingQueue用于实现生产者和消费者一个不错的选择 它可以很自然的实现作为生产者和消费者的内存缓冲区
但是BlockingQueue并不是一个高性能的实现 它完全使用锁和阻塞等待实现线程间的同步 在高并发场合 它的性能并不是特别的卓越 就像之前已经提过的ConcurrentLinkedQueue是一个高性能的队列 但是BlockingQueue只是为了方便数据共享
5.4.1 无锁的缓存框架:Disruptor
Disruptor是由LMAX公司开发的一款高效的无锁内存队列 它使用无锁的方式实现了一个环形队列 非常适合于实现生产者和消费者模式 比如事件和消息的发布 在Disruptor中 别出心裁的使用了环形队列(RingBuffer)来代替普通线性队列 这个环形队列内部实现为一个普通的数组 对于一般的队列 势必要提供队列同步head和尾部tail俩个指针 用于出队入队 增加了线程协作的复杂度 但是如果队列是环形的 则只需要对外提供一个当前位置cursor 利用这个指针即可以入队也可以进行出队操作 由于环形队列的缘故 队列的总大小必须事先指定 不能动态扩展 为了能快速从一个序列对应数组的实际位置(每次有元素入队 序列就加1),Disruptor要求我们必须将数组的大小设置为2的整数次方这样通过sequence&(queueSize-1)就能立即定位到实际的元素位置index 这个要比取余(%)操作快得多
如果大家不理解上面的sequence&(queueSize-1) 在这里简单说明一下 如果queueSize是2的整数次幂 则这个数字的二进制表示比如是10,100,1000 等形式 因此queueSize-1的二进制是一个全1的数字 因此它可以将sequnce限定在queueSize-1的范围内 并且不会有任何一位是浪费的

相关代码请见Disruptor案例
Disruptor至少要比BlockingQueue要高一个量级以上
5.4.3 提高消费者的响应时间:选择合适的策略
当有新数据在Disruptor的环形缓冲区中产生时 消费者如何知道这些新产生的数据呢 或者说 消费者如何监控缓冲区中的信息呢 为此 Disruptor提供了几种策略 这些策略由WaitStrategy接口封装 主要有以下几种实现
- BlockingWaitStrategy:这是默认的策略 使用BlockingWaitStrategy和使用BlockingQueue是非常类似的 它们都使用锁和条件(Condition)进行数据的监控和线程的唤醒 因为涉及到线程的切换 BlockingWaitStrategy策略是最节省CPU 但是在高并发下性能表现最糟糕的一种等待策略
- SleepingWaitStrategy:这个策略也是对CPU使用率非常保守的 它会在循环中不断等待数据 它会先进行自旋等待 如果不成功 则使用Thread.yiled()让出cpu 并最终使用LockSupport.parkNanos(1)进行线程休眠 以确保不占用太多的CPU数据 因此 这个策略对于数据处理可能产生比较高的平均延时 它比较适合于延时要求不是特别高的场合 好处是它对生产者线程影响最小 典型的应用场景是异步日志
- YiedldingWaitStrategy:这个策略用于低延时的场合 消费者线程会不断循环监控缓冲区变化 在循环内部 它会使用Thread.yield()让出CPU给别的线程执行时间 如果你需要一个高性能的系统 并且对延时有较为严格的要求 则可以考虑这种策略 使用这种策略时 相当于你的消费者线程变身为一个内部执行了Thread.yield()的死循环 因此 你最好有多余消费者线程数量的逻辑CPU数量(这里的逻辑CPU 指的是“双核四线程”中的四线程 否则 整个应用程序恐怕都会受到影响)
- BusySpinWaitStrategy:这个是最疯狂的等待策略 它就是一个死循环! 消费者线程会尽最大努力疯狂的监控缓冲区的变化 因此 它会吃掉所有的CPU资源 你只有在延时非常苛刻的场合可以考虑使用它(或者说 你的系统真的非常繁忙) 因为在这里你等同开启了一个死循环监控 所以你的物理CPU必须要大于消费者线程数 注意 这里说的是物理CPU 不是超线程技术模拟的俩个逻辑核 另外一个逻辑核显然会受到这种超密集计算的影响而不能正常工作
5.4.4 CPU cache的优化:解决伪共享问题
除了使用CAS和提供了各种不同的等待策略来提高系统的吞吐量外 Disruptor大有优化到底的气势 甚至尝试解决CPU缓存的伪共享问题
什么是伪共享问题 为了提高CPU的速度 CPU有一个高速缓存cache 在高速缓存中 读写数据最小单位为缓存行(Cache line) 它是从主存(memory)复制到缓存(Cache)的最小单位 一般为32字节到128字节
如果俩个变量存放在一个缓存行中 在多线程访问时可能会相互影响彼此的性能
为了不使这种情况发生 一种可行的方法就是在变量的前后都先占据一定的位置(叫做padding吧) 这样 当内存被读入缓存时 这个缓存行 只有这个变量是实际有效的 因此就不会发生多个线程修改缓存行中不同变量而导致变量全体失效的情况
相关代码请见 FlaseSharing.java
在代码的55行 准备了7个long型变量来填充缓存 实际上 只有VolatileLong.value是被使用的 而那写p1,p2等仅仅用于将数组中第一个VolatileLong.value和第二个VolatileLong.value分开 防止它们进入同一个缓存行
注意 由于各个JDK版本内部实现不一致 在某些JDK版本中(比如JDK8)会自动优化不使用的字段 这将直接导致这种padding的伪共享问题解决方案失效 更多详细内容到第6章有关LongAddr的介绍
在Disruptor内部充分考虑了这个问题
1 | public final class PaddedLong extends MutableLong |
5.5 Future模式
Future模式是多线程开发中非常常见的一种设计模式 它的核心思想是异步调用

5.5.1 Future模式的主要角色
| 参与者 | 作用 |
|---|---|
| Main | 系统启动 调用Client发出请求 |
| Client | 返回Data对象 立即返回FutreData并开启ClientThread线程装配RealData |
| FutureData | Future数据 构造很快 但是是一个虚拟的数据 需要装配RealData |
| RealData | 真实数据 其构造是比较慢的 |
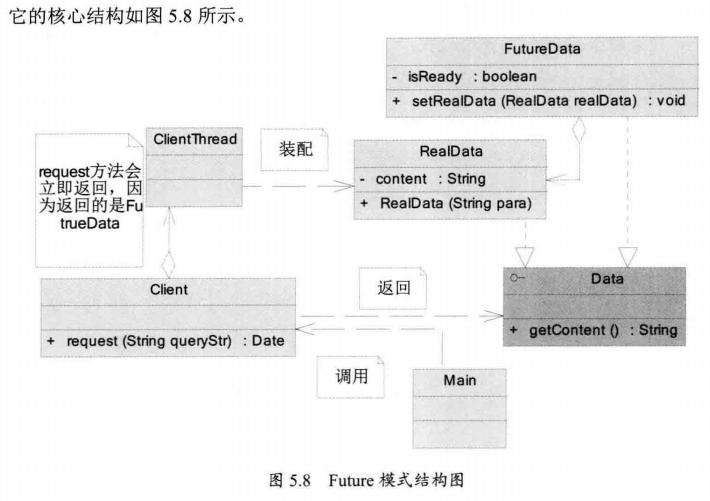
5.5.2 Future模式的简单实现
有一个核心接口Data 这就是客户端想要的数据
在Futre模式中 这个接口有俩个重要的实现 一个是RealData 也就是真实数据 一个是FutureData 只是用来提取RealData的一个订单
因此FutureData是可以立即返回的
1 | public interface Data { |
FuturData实现了一个快速返回 它只是一个包装 或者说是一个RealData的虚拟实现 因此 它可以很快被构造并返回 当使用FutureData的getResult()方法时 如果实际的数据没有准备好 那么程序就会被阻塞 等待RealData准备好并注入到FutureData中 才最终返回数据
FuturData是Future模式的关键 它实际上是真实数据RealData的代理 封装了获取RealData的等待过程
相关代码请见Future模式
5.5.3 Jdk内部的Future模式
RunnablFuture继承了Future和Runnable俩个接口 其中run()方法用于构造真实的数据 它有一个具体的实现FutureTask类
FutureTask有一个内部类Sync 一些实质性的工作 会委托给Sync类实现 而Sync类最终会调用Callable接口 完成实际数据的组装工作

Callable接口只有一个方法call() 它会发货需要构造的实际数据 这个Callable接口也是这个Future框架和应用程序之间的重要接口 如果我们要实现自己的业务系统 通常需要实现自己的Callable对象 此外FutureTask类也与应用密切关联
5.6 并行流水线
并发算法虽然可以充分发挥多核CPU的性能 但不幸的是 并非所有的计算都可以改造成并发的形式 简单的说 执行过程中有数据相关性的运算都是无法完美并行化的
比如(B+C)B/2 这个过程就无法并行的 原因是 如果B+C无法完成 则永远算不出(B+C)B 这就是数据相关性 如果线程执行过程中 所需的数据存在这种依赖关系 那么 就没有办法将它们完美的并行化
遇到这种情况 补救措施就是采用日常生活中的流水线思想
相关代码请见并行计算
5.7 并行搜索
搜索是几乎每个软件都有个功能 对于有序数据 通常可以采用二分法 对于无序数据 只能挨个查找
给定一个数组 要查找满足条件的元素 对于串行程序来说 只要遍历一下数组就可以得到结果 但如果要使用并行方式 则需要额外增加一些线程间的通信机制 使各个线程可以有效的运行
一种简单的策略就是将原始数据集合按照期望的线程数进行分割,如果我们计划使用俩个线程进行搜索 那么就可以把一个数组或集合分割成俩个 每个线程各自的独立搜索 当其中有一个线程找到数据后 立即返回结果即可
相关代码请见 SearchDemo.java
5.8 并行排序
排序是一个非常常用的操作 在应用程序运行时 无时无刻不在排序
当排序元素有很多时 若使用并行算法代替串行算法 显然可以更加有效的利用CPU 但将串行算法改造为并行算法并非易事 甚至会极大的增强原有算法的复杂度
这里介绍几个简单平行排序算法
5.8.1 分离数据相关性:奇偶交换排序
奇偶排序是对冒泡排序的并行改造
在SerialSort.java中有相关冒泡排序的代码
对于奇偶排序来说 它将排序分为俩个阶段 奇交换与偶交换 对于奇交换来说 它总是比较奇数索引以及相邻的后续元素 而偶交换总是比较偶数索引和其相邻的后续元素 并且 奇交换与偶交换会成对出现 这样才能保证比较和交换涉及到数组中的每一个元素
奇偶交换的串行实现也在SerialSort.java中有相关代码
这样的代码虽然是串行代码 但是已经很好改造为并行模式了
相关代码请见OddEventSort.java
5.8.2 改进的插入排序:希尔排序
插入排序也是一种很常用的排序算法
在SerialSort.java中有相关插入排序的代码
简单的插入排序是很难并行化的 因为这一次的数据插入依赖上一次得到的有序排列 因此多个步骤是无法并行的
希尔排序将整个数组根据间隔h分割为若干个子数组 子数组相互穿插在一起 每一次的排序时 分别对每一个子数组进行排序
在每一组排序完成后 可以递减h的值 进行下轮更加精细的排序 直到h为1 此时等价于一次插入排序
并行排序的一个主要优点是,即使一个较小的元素在数组的末尾 由于每次元素移动都以h为间隔进行 因此数组末尾的小元素可以在很少的交换次数下 就被置换到最接近元素最终位置的地方
希尔排序的串行实现
相关代码请见SerialSort.java
希尔排序就很好改造为并行程序了
相关代码请见ShellSort.java
5.9 并行算法:矩阵算法
同第四章的无锁Vector一样 不好找具体工具 就不再说明了
5.10 准备好了再通知我:网络NIO
Java NIO是NEW IO的简称 它是一种可以替代Java IO的一套新的IO机制 它提供了一套不同于java标准的IO的操作机制 严格来说 NIO与并发无直接的关系 但是 使用NIO技术可以大大的提高线程的使用效率
Java NIO涉及的基础内容有通道(Channel)和缓冲区(Buffer),文件IO和网络IO 有关通道,缓冲区以及文件IO在这里不打算进行详细的介绍
5.10.1 基于Socket的服务端的多线程模式
这里 以一个简单的Echo服务器为例 对于Echo服务器 它会读取客户端的一个输入 并将这个输入原封不动的返回给客户端
相关代码请见 MultiThreadEchoServer.java
这是一个支持多线程的服务端的核心内容 它的特点是 在相同可支持的线程访问内 可以尽量多地支持客户端的数量 同时和单线程服务器相比 它可以更好的支持多核CPU
相关代码请见MultiThreadEchoClient.java
对于绝大部分应用来说 这种模式可以很好地工作 但是 如果想让你的程序工作更加高效 就必须知道这个模式一个重大的弱点 那就是倾向于让CPU进行IO等待
下面有个清晰的例子
HeavySocketClient.java
之所以处理的慢 并不是因为服务端有多少繁重的业务 而仅仅是因为服务线程在等待IO而已 让高速运转的CPU去等待极其低效的网络IO是非常不合算的行为
是不是可以将网络IO的等待时间从线程中分离出来呢?
5.10.2 使用NIO进行网络编程
首先知道NIO中的一个关键组件Channel(通道)Channel有点类似于流 一个Channel可以和文件或者网络Socket对应 如果Channel对应一个Socket 那么往这个Channel中写数据 就等于往Socket中写数据
和Channel一起使用的另外一个重要组件就是Buffer 大家可以简单的把Buffer理解成一个内存区或者Byte数组 数据需要包装成Buffer的形式才能和Channel交互(写入或读取)
另外一个与Channel密切相关的是Selector(选择器) 在Channel众多实现中 SelectableChannel实现 表示可被选择的通道
任何一个SelectableChannel都可以将自己注册到一个Selector中 这样这个Channel就能被Selector所管理 而一个Selector可以管理多个SelectableChannel 当SelectableChannel的数据准备好时 Selector就会接到通知 得到那写已经准备好的数据 而SocketChannel就是SelectableChannel的一种
这样的话 一个Selector可以由一个线程进行管理 而一个SocketChannel则可以表示一个客户端连接 因此就构成由一个或者极少数线程 来处理大量客户端连接的结构 当与客户端连接的数据没有准备好时 Selector会处于等待状态(不过 幸好 用于管理Selector的线程是极少量的) 而一旦有任何一个SocketChannel准备好了数据 Selector就能立即得到通知 获取数据进行处理
相关代码请见NioServerSocket.java
5.10.3 使用NIO来实现客户端
相关代码请见 NioSocketClient.java
5.11 读完了再通知我:AIO
AIO是异步IO的缩小 即Asynchronized 虽然NIO在网络操作中 提供了非阻塞的方法 但是NIO的IO行为还是同步的 对于NIO来说 我们的业务线程是在IO操作准备好时 得到通知 接着就由这个线程自行进行IO操作 IO操作本身还是同步的
但是对AIO来说 就更进一步 它不是在IO准备好时再通知线程 而是在IO操作已经完成后 再给线程发出通知 因此AIO是完全不会阻塞的 此时 我们的业务逻辑将变为一个回调函数 等待IO操作完成后 由系统自动触发
5.11.1 AIO EchoServer的实现
相关代码请见AioEchoServer.java
5.11.2 AIO Echo客户端实现
相关代码请见AioEchoClient.java
第六章 Java8与并发
6.1 Java8的函数式编程简介
6.1.1 函数作为一等公民
函数可以作为另外一个函数的返回值 这也是函数式编程的特点
6.1.2 无副作用
函数的副作用指的是在调用过程中 除了给出了返回值外 还修改了函数状态 比如 函数在调用过程中 修改了某一个全局状态 函数式编程认为,函数的副作用应该被尽量避免
显示函数指函数与外界交换数据的唯一渠道就是参数和返回值 显示函数不会去读取或者修改函数的外部状态 与之相对的是隐式函数 隐式函数除了参数和返回值外 还会读取外部信息 或者可能修改外部信息
完全的无副作用实际上做不到的 因为系统总是需要获取或者修改外部信息的
6.1.3 申明式的(Declarative)
函数式编程是申明式的编程方式,相对于命令式(Imperative)而言 命令式的程序设计喜欢大量使用可变对象和指令
在申明式的编程范式 你不再需要提供明确的指令操作 所有的细节指令将会更好地被程序库所封装 你要做的只是提出你的需求 申明你的用意即可
1 | int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9,10}; |
与之对应的申明式代码如下
1 | int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9,10}; |
在此 我们只是简单的申明了我们的用意 有关循环以及判断是否结束等操作都被简单地封装在程序库中
6.1.4 不变的对象
在函数式编程中 几乎所有传递的对象都不会被轻易修改
例子如下
1 | static int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9,10}; |
在使用函数式编程时 这种状态是一种常态 几乎所有的对象都拒绝被修改 这非常类似于不变模式
6.1.5 易于并行
由于对象都处于不变的状态 因此函数式编程更加易于并行 我们之所以要关注线程安全 一个很重要的原因是当多个线程对同一个对象进行写操作 容易将这个对象”写坏” 但是 由于对象是不变的 因此 在多线程环境下 也就没有必要进行任何同步操作
6.1.6 更少的代码
通常情况下 函数式编程更加简明扼要 代码更少
6.2 函数式编程基础
Java 8 提出了函数式接口的概念 所谓函数式接口 简单来说 就是只定义了的单一抽象方法的接口
1 | @FunctionalInterface |
注释FunctionInterface用于表明Runnable是一个函数式接口 该接口被定义为只包含一个抽象方法run() 因此它符合函数式接口的设计 如果一个函数满足函数式接口的定义 那么即使不标注为@FunctionInterface 编译器依然会把它看做函数式接口 这有点像@Overried注释 如果你的函数符合重载的要求 无论你是否标注了@Overried 编译器都识别这个重载函数 但一旦你进行了标注 而实际的代码不符合规范 那么就会得到一个编译错误
这里需要强调的是 函数式接口只能有一个抽象方法 而不是只能有一个方法 这份俩点来说 在java8中 接口运行存在实例方法 比如默认方法 静态方法 其次 如何被java.lang.Object实现的方法 都不能视为抽象方法
6.2.2 接口默认方法
6.2.4 方法引用
6.3 一步一步走入函数式编程
关于这几章其实我在博客中的另外一篇博客 JAVA8新特性总结中已经介绍过了
6.4 并行流与并行排序
6.4.1 使用并行流过滤数据
1 | public class PrimeUtil { |
可以使用parallel()方法得到一个并行流 接着 在并行流进行过滤 此时 PrimeUtil.isPrime()会被多线程并发调用 应用于流的所有元素
6.4.2 从集合得到并行流
在函数式编程中 我们可以从集合得到一个流或者并行流
1 | List<Student> ss = new AskThread(); |
在集合对象List中 我们使用stream()方法可以得到一个流 如果希望将这段代码并行化 则可以使用parallelStream()函数
1 | double ave=ss.parallelStream().mapToInt(s->s.score).avarage().getAsDouble(); |
6.4.3 并行排序
除了并行流外 对于普通数组 Java8中也提供了简单的并行功能 比如 对于数组排序 有Arrays.sort()方法 当然这是串行排序 在Java8中也有新增的Arrays.paralleSort()
1 | int[] arr = new int[10]; |
除了并行排序外 Arrays中还增加了一些API用于数组中数据的赋值
1 | Random r = new Random(); |
6.5 增强的Future:CompletableFuture
CompleteableFuture是Java8新增的一个超大型工具类 为什么说它大呢 一方面是实现了Future接口 更重要的是实现了CompletionStage接口
这个接口含有多达约40种方法 之所以这么多方法 视为了函数式编程的流式调用准备的 通过CompletionStage提供的接口 我们可以在一个执行结果上多次流式调用 以此得到最终结果
6.5.1 完成了就通知我
CompletableFutre与Future一样 可以作为函数调用的契约 如果你向CpmpletableFuture请求一个数据 如果数据还没有准备好 请求线程就会等待 而让人惊喜的是 CompletableFuture是可以手动设置完成状态的
相关代码请见AskThread.java
6.5.2 异步执行任务
通过将CCpmletableFuture提供的进一步封装 我们很容易实现Future模式那样的异步调用
1 | public static Integer calc(Integer para){ |
上述代码中 使用了一个CompletableFuture.supplyAsync()方法构造一个CompletableFuture实例 在supplyAsync()函数中 它会在一个新的线程中 执行传入的参数 在这里 它会执行calc()方法 而calc()方法执行是比较慢的 但是这不影响CompletableFuture实例的构造速度 因此supplyAsync()会理解返回 它返回的CompletableFuture对象实例 在supplyAsync()函数中 它会在一个新的线程中 执行传入的参数 但这不影响CompletableFuture实例的构造速度 因此supplyAsync()会立即返回
它返回的CompletableFuture对象实例就可以作为这次调用的契约 在将来的任何场合 用于获得最终的计算结果
如果当前计算没有完成 则调用get()方法的线程会等待
在CompletableFuture中 类似的工厂方法有以下几个
1 | public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) |
上述代码中 使用supplyAsync()函数执行一个异步任务 接着连续使用流式调用对任务的处理结果进行再加工 直到最后结果输出
6.5.4 CompletableFuture中的异常处理
CompletableFuture提供了一个异常处理方法execptionally();
1 | public static Integer calc(Integer para){ |
在上述代码中 第8行对当前的CompletableFuture进行异常处理 如果没有异常发生 则CompletableFuture就会返回原有的结果 如果遇到了异常 就可以在exceptionally()中处理异常 并返回一个默认的值
6.5.5 组合多个CompletableFuture
CompletableFuture还允许你将多个CompletableFuture进行组合 一种方法是使用thenCompose()
一个CompletableFuture可以在执行完成后 将执行结果通过Function传递给下一个CompletionStage进行处理(Function接口返回新的CompletionStage实例)
1 | public static Integer calc(Integer para){ |
另外一种组合多个CompletableFuture的方法是thenCombine()
1 | public static Integer calc(Integer para){ |
上述代码中 首先生成俩个CompletableFuture实例 接着使用thenCombine()组合将这俩个CompletableFuture 将这俩者的执行结果进行累加 并将其累加结果转换为字符串
6.6 读写锁的改进:StampedLock
StampedLock是java8引入的一种新的锁机制 简单的理解 可以认为它是读写锁的一个改进版本 读写锁虽然分离了读与写 使得读与读之间可以完全并发 但是 读和写之间依然是冲突的 读锁会完全阻塞写锁 它使用的依然是悲观的锁策略 如果有大量的读线程 也有可能会引起写线程的“饥饿”
而StampedLock是一种乐观的读策略 这种乐观的锁非常类似无锁的操作 使得乐观锁完全不会阻塞写线程
6.6.1 StampedLock使用示例
相关代码请见Point.java
在上述代码中 使用了StampedLock.trtOptimisticRead()方法 这个方法表示试图尝试一次乐观锁 它会返回一个类似于时间戳的邮戳整数stamp 这个stamp就可以作为这一次锁获取的凭证
其中有一个validate()方法 这个方法用来判断这个stamp是否在读过程发生期间被修改过 如果stamp没有被修改过 则认为这次读取是有效的 就可以进行数据处理 反之 如果stamp不可用 则意味着在读取的过程中 可能被其他线程改写了数据 因此 有可能出现脏读 如果出现这种情况 我们可以像处理CAS操作那样在一个死循环中一直使用乐观锁 直到成功为止
也可以升级锁的级别 在本例中 就升级为了悲观锁 如果当前对象正被修改 读操作就会导致线程被挂起
可以看到 StampedLock通过引入乐观锁来增加系统的并行度
6.6.2 StampedLock的小陷阱
StampedLock内部实现时 使用类似CAS操作的死循环反复尝试的策略
在它挂起线程时 使用的是Unsafe.park()函数 而park()函数在遇到线程中断时 会直接返回(注意,不同于Thread.sleep()它不会直接抛出异常)
而在StampedLock的死循环逻辑中 没有处理有关中断的逻辑 因此 这就会导致阻塞在park()上的线程被中断后 会再次进入循环 而当退出条件得不到满足时 就会发生疯狂占用CPU的情况 这一点值得注意
下面的例子演示了这个问题
StampedLockCPUDemo.java
6.6.3 有关StampedLock的实现思想
StampedLock的内部实现是基于CLH锁的 CLH锁是一种自旋锁 它保证没有饥饿发生 并且可以保证FIFO(First-In-First-Out)的服务顺序
CLH锁的基本思想如下:
锁维护一个等待线程队列 所有申请锁 但是没有成功的线程都记录在这个队列中 每一个节点(一个节点代表一个线程) ,保存一个标志位(Locked),用于判断当前线程是否已经释放锁
当一个线程试图获得锁,取得当前等待队列的尾部结点作为其前序节点 并使用类似如下代码判断前序节点是否已经成功释放锁
1 | while(pred.locked){ |
只要前序节点(pred)没有释放锁 则表示当前线程还不能继续运行 因此会自旋等待
反之 如果前序线程已经释放锁 则当前线程可以继续执行
释放锁时 也遵循这个逻辑 线程会将自身节点的locked位置标记为false 那么后续等待的线程就能继续执行了
StampedLock正是基于这种思想 但是实现上更为复杂
在StampedLock内部 会维护一个等待链表队列
1 | static final class WNode { |
上述代码中 WNode为链表的基本元素 每一个WNode表示一个等待线程 字段whead和wtail分别指向等待链表的头部和尾部
另外一个很重要的字段state
1 | /** Lock sequence/state */ |
字段state表示当前锁的状态 它是一个long型 有64位 其中 倒数第8位表示写锁状态 如果该位为1 表示当前由写锁占领
1 | public long tryOptimisticRead() { |
一次成功的乐观锁必须保证当前锁没有写锁占用 其中WBIT用来获取写锁状态位 值为0X80 如果成功 则返回当前state的值(末尾7位清零,末尾7位表示当前正在读取的线程数量)
如果在乐观锁读后 有线程申请了写锁 那么state的状态就会改变
1 | public long writeLock() { |
上述代码第4行 设置写锁位为1(通过加上WBIT(0x80)) 这样 就会改变state的取值 那么在乐观锁确认时(validate)时 就会发现这个改动 导致乐观锁失效
1 | public boolean validate(long stamp) { |
上述validate()函数比较当前stamp和发生乐观锁时取得的stamp,如果不一致 则宣告乐观锁失败
乐观锁失败后 可以提高锁级别 升级为悲观锁
1 | public long readLock() { |
悲观锁会尝试设置state状态(第4行) 它会将state加1(前提是读线程数量没有溢出,对于读线程数量溢出的情况 会使用辅助的readerOverflow进行统计 这里不讨论)用于统计线程的数量 如果失败 则进入acquireRead()二次尝试锁获取
在acquireRead()中 线程会在不同条件下进行若干次自旋 试图通过CAS操作获得锁 如果自旋宣告失败 则会启用CLH队列 将自己加入到队列中 之后再启用自旋 如果发现自己成功获得了读锁 则会进一步把自己cowait队列中的读线程全部激活(使用Unsafe.unpark()方法) 如果最终依然无法成功获得读锁 则会使用Unsafe.park()方法挂起当前线程
方法acquireWrite()和acquireRead()也非常类似 也是通过自旋尝试 加入等待队列 直至最终Unsafe.park()方法挂起线程的逻辑进行的 释放锁时与加锁动作想法 以unlockWrite()为例
1 | public void unlockWrite(long stamp) { |
上述代码第5行 将写标识位清理 如果state发生溢出 则退回到初始值
接着 如果等待队列不为空 则从等待队列中激活一个线程(绝大多数情况下是第一个等待线程)继续执行(第7行)
6.7 原子类的增强
6.7.1 更快的原子类
在AtomicInteger类中 它们都是在一个死循环中 不断尝试修改目标值 直到修改成功 如果竞争不激烈的情况下 修改成功率很高 否则 修改失败的概率就会很高 在大量修改失败时 这些原子操作就会进行多次循环尝试 因此性能就会受到影响
那么当竞争激烈的时候 有一种方案可以使用热点分离 将竞争的数据进行分解 提高系统的性能 基于这种思路 虽然CAS操作中没有锁 但是像减小锁粒度这种分离热点的思想依然可以使用
一种可行的方案就是仿造ConcurrentHashMap 将热点数据分离 比如 可以将AtomicInteger的内部核心数据value分离成一个数组 每个线程访问时 通过哈希等算法映射到其中一个数字进行计数 而最终的计算结果 则为这个数组的求和累加
而LongAddrer正是使用了这种思想
在实际的操作中 LongAdder并不会一开始就动用数组进行处理 而是将所有数据都先记录在一个称为base的变量中 如果在多线程条件下 大家修改base都没有冲突 那么也没有必要扩展为cell数组 但是一旦发现base修改发生冲突 就会初始化cell数组 使用新的策略 如果使用cell数组更新后 发现某一个cell上的更新依然发生冲突 那么系统就会尝试创新的cell 或者将cell的数量加倍 以减少冲突的可能
简单的分析一个increment()方法的内部实现
1 | public void increment() { |
它的核心是第4行的add()方法 最开始cells为null 因此数据会向base增加 但是如果对base的操作冲突 则会进入第7行 并设置冲突标记uncontended为true 接着
如果判断cells数组不可用 或者当前线程对应的cell为null 则直接进入longAccumulate()方法 否则会尝试使用CAS方法更新对应的cell数据 如果成功 则退出 失败则进入longAccumulate()方法
longAccumulate()方法比较复杂 其大致内容为根据需要创建新的cell或者对cell数组进行扩容 以减少冲突
下面进行一个例子简单的对LongAdder,原子类以及同步锁进行性能测试 测试方法是使用多个线程对同一个整数进行累加 观察使用3种不同方法所消耗的时间
LongAdderDemo.java
这本书说的是LongAdder的表现最好 但是可能是因为我是i5的cpu只有双核 速度表现并不理想 最好的是原子类
LongAdder的另外一个优化手段就是避免了伪共享 在第5章有有关伪共享的问题 但是 需要注意的是 LongAdder中并不是直接使用padding这种看起来比较碍眼的做法 而是引入了一种新的注释'@sun.misc.Contended‘
1 | @sun.misc.Contended static final class Cell { |
可以看到 在上述代码第一行申明了Cell类为sun.misc.Contended 这将会使得Java虚拟机自动为Cell解决伪共享问题
当然 在我们的代码中也可以使用sun.misc.Contened来解决伪共享问题 但是需要额外使用虚拟机参数-XX:-RestrictConteded 否则 这个注释将被忽略
6.7.2 LongAdder的功能增强版:LongAccumulator
LongAccumulator是LongAdder的亲兄弟 它们有公共的Striped64 因此 LongAccumulator的内部的优化方式和LongAdder是一样的 它们都有一个long型的整数进行分割 存储在不同的变量中 以防止多线程竞争 俩者的主要逻辑是类似的 但是LongAccumulator是LongAdder的功能扩展 对于LongAdder来说 它只是每次对给定的整数执行一次加法 而LongAccumulator则可以用任意函数操作
可以使用下面的构造函数创建一个LongAccumulator实例
1 | public LongAccumulator(LongBinaryOperator accumulatorFunction, |
第一个参数accumulatorFunction就是需要执行的二元函数(接受俩个long行参数并返回long),第二个参数是初始值
下面那个例子展示了LongAccumulator的使用 它将通过多线程访问若干个整数 并返回遇到的最大的那个数字
相关代码请见LongAccumulatorDemo.java
在上述代码中 构造了LongAccumulator实例 并且过滤了最大值 因此传入Long::max函数句柄 当有数据通过accumulate()方法传入LongAccumulator后 LongAccumulator会通过Long::max识别最大值并且保存在内部 在第24行 通过longValue()函数对所有的cell进行了Long::max操作 得到最大值
第7章 使用AKKA构建高并发程序
写出一个高并发并且可扩展的应用是很难的 那么是否有一个好的框架可以帮助我们轻松构建这么一个应用呢 Akka提供了这么一个方式 Akka是遵循Apache2许可的开源人员 这意味你可以无偿并且几乎没有限制的使用它 包括应用商业环境
Akka是使用scala创建的 但是Scala和java一样 都是jvm上的内容 都可以互相调用 但是实际使用中 还是推荐使用Scala来进行Akka的编写
Akka提供了一种Actor的并发模型 其粒度比线程更小 可以在代码中启用极其大量的Actor
其次 Akka中提供了一套容错机制 运行在Actor出现异常时进行一些恢复或者重置操作
最后 通过Akka不仅可以在单机上构建高并发程序 也可以在网络上构建分布式程序
并提供位置透明的Actor定位服务
7.1 新并发模型:Actor
在使用Akka中 基本就可以忘记线程了 当你使用Akka时 就有了一个全新的执行单元-Actor
Actor可以比喻为一个人 多个人之间可以通过语言交流
传统Java并行程序 还是完全基于对象的方法 我们还是通过对象的方法调用进行信息的传递 这时 如果对象的方法会修改对象本身的状态 那么在多线程情况下 就有可能出现对象状态的不一致 所以我们就必须对这类方法调用进行同步 当然 同步往往是以牺牲性能为代价的
在Actor模型中 我们失去了对象的方法调用 我们不是通过调用Actor对象的某一个方法来告诉Actor你需要做什么 而是给Actor发生一条消息 当一个Actor收到消息后 它有可能会根据消息的内容做出某些行为 包括更改自身状态 但是 在这种情况下 这个状态的更改是Actor自己进行的 并不是由外界强迫进行的
7.2 Akka之Hello World
一个Acotr的实现
Greeter.java
HelloWorld.java
上述代码中 定义了一个换一种Greeter 继承自UntypedActor(它自然是Akka中的核心成员了) UntypedActor就是我们说的Actor 之所以说是无类型 是因为还有一种有类型 有类型的Actor可以使用系统中的 其他类型构造 可以缓解Java单继承的问题 因为你在继承UntypedActor后 就不能再继承系统中其他类了 如果你一定想这么做 那么就只能选择有类型的Actor 否则UntypedActor就是你的首选
在HelloWorld.java中又实现了一个HelloWorld的Actor 其中的preStart()方法为Akka的回调方法 在Actor启动前 会在Akka框架调用,完成一些初始化的工作
在这里 由于创建Greeter时使用的是HelloWorld的上下文 因此 它属于HelloWorld的子Actor
onReceive()函数是为HelloWorld的消息处理函数
主函数如下:
HelloWorldMain.java
在主函数中 创建了ActorSystem 表示管理和维护Actor的系统 一般来说 一个应用程序只需要一个ActorSystem就够用了 ActorSystem.create()的第一个参数‘hello’为系统名称 第2个参数为配置文件
通过AcotorSystem创建一个顶级的Acotor(HelloWorld)
可以看到 当使用Actor的时候 关注点已经不在线程上了 实际上 线程调度已经被Akka框架进行了封装 只需关注Actor对象即可 而Actor对象之间的交流和普通对象的函数调用有明显区别 它们是通过显示的消息发送来传递消息的
当系统有多个Actor存在时 Akka会自动在线程池中选择线程来执行我们的Actor 因此 当多个不同的Actor可能被同一个线程执行 同时 一个Actor也有可能被不同线程执行 因此 一个值得注意的地方是:不要在一个Actor中执行耗时的代码 这样可能会导致其他Actor的调度出现问题
7.3 有关消息投递的一些说明
整个Akka应用是由消息驱动的 消息是除了Actor之外最重要的核心组件 作为在并发程序中的核心组件 在Actor之间传递应该满足不变性 也就是不变模式 因为可变模式无法高效的在并发环境使用 理论上Akka的消息可以使用任何对象实例 但实际使用中 强烈推荐使用不可变模式
实际上 对于消息投递 可以有3种不同的策略
- 第一种 称为最多一次传递 每条消息最多投递一次 在这种情况 偶尔会有投递失败 从而导致消息丢失
- 第二种 称为最少一次投递 每一条消息至少会被投递一次 直到成功为止 在一些偶然的场合 接受者可能会受到重复的消息 但不会发生消息丢失
- 第三种 称为精准的消息传递,也就是所有的消息精准地投递并成功接收一次 既不会有丢失 也不会重复接收
很明显 第一种性能最好 第二种其次 第三种 成本最高 最难以实现
那么是否真的需要保证消息投递的可靠性呢
答案是否定的 实际上 我们没有必要在Akka层保证消息的可靠性 这样做 成本太高了 也是没有必要的 消息的可靠性更应该在应用的业务层去维护 因为也许在有些时候 丢失一些消息完全是符合应用要求的 因此在使用Akka时 需要在业务层对此进行保证
此外 对于消息投递Akka可以在一定程度上保证顺序性 比如Actor A1向A2顺序发送M1,M2和M3三条消息 Actor A3向A2顺序发送了M4,M5和M6三条消息
- 如果M1没有丢失 那它一定先于M2和M3被A2收到
- 如果M2没有丢失 那它一定先于M3被A2收到
- 如果M4没有丢失 那它一定先于M5和M6被A2收到
- 如果M5没有丢失 那它一定先于M6被A2收到
- 对A2来说 来自A1和A3的消息可能交织在一起 没有顺序保证
在这里 值得注意的一点是,这种消息投递规则不具备可传递性 比如:
Actor A向C发生M1,接着Actor A向B发送了M2,B将M2转发给Actor C那么在这种情况下 C收到M1和M2的先后顺序是没有保证的
7.4 Actor的生命周期
一个Actor在actorOf()函数被调用后开始建立 Actor实例创建后 会回调preStart()方法 在这个方法里面 可以进行一些资源的初始化工作 在Actor的工作过程中 可能会出现一些异常 这种情况下 Actor会重启 当Actor被重启时 会回调preRestart()方法 (在老的实例上)接着系统会创建一个新的Actor对象实例(虽然是新的实例,但它们都表示同一个Actor)当新的Actor实例创建后 会回调postRestart()方法 表示启动完成 同时新的实例将会代替旧的实例 停止一个Actor也有很多方式 你可以调用Stop()方法或者给Actor发送一个PosionPill Actor停止后 postStop()方法会被调用 同时这个Actor的监听者会受到一个Terminated消息
下面是一个既带有生命周期回调函数的Actor
MyWorker.java
另外为MyWoker指定了一个监听者
WatcherActor.java
本质上,它也是一个Actor 但不同的是 它会在它的上下文中watch一个Actor 如果将来这个被监视的Actor的退出终止 WatchActor就能收到一条Terminated消息 在这里 我们将简单地打印终止消息Terminated的相关Actor路径 并且关闭整个ActorSystem
主函数如下
DeadMain.java
注意在创建WatchActor的时候 第一个参数为要创建的Actor类型 第2个参数为这个Actor的构造函数的参数(在这里 就是要调用WatchActor的构造函数)
7.5 监督策略
如果一个Actor在执行过程中发生意外 比如没有处理某些异常 导致出错 那么这个时候该怎么办
对于这种情况 Akka框架给予了我们足够的控制权 在Akka框架内 父Actor可以对子Actor进行监督 监控Actor的行为是否有异常 大体上 监督策略可以分为俩种 一种是OneForOneStrategy的监督 另外一种是AllForOneStrategy
对于OneForOneStrategy的策略 父Actor只会对出问题的子Actor进行处理 比如重启或者停止 而对于AllForOneStrategy 父Actor会对出问题的子Actor以及它所有的兄弟类进行处理 很显然 对于AllForStrategy策略 它更适合对各个Actor联系紧密的场景 如果多个Actor间只要一个Actor出现故障 则宣告整个任务的失败 就比较适合使用AllForStrategy 否则 在更多的场景中 应该使用OneForOneStrategy
当然 这也是Akka中的默认策略
要指定这些监督行为 只要构造一个自定义的监督策略即可
首先定义一个父Actor 它作为所有子Actor的监督者
Supervisor.java
上述代码 定义了一个OneForOneStrategy监督策略 在这个策略中 运行Actor在遇到错误后 在1分钟内进行3次重试 如果超过这个频率 那么就会直接杀死actor
32-34行覆盖父类的supervisorStrategy()方法 设置使用自定义的监督策略
第39行用来新建一个名为restartActor的子Actor 这个子Actor就由当前的supervisor进行监督 当Supervisor接受一个Props对象时 就会更加这个Props配置生成一个restartActor
RestartActor的实现如下
RestartActor.java
定义了一些Actor的生命周期的回调接口 目的是更好的观察Actor的活动情况 在32-34行模拟了一些异常情况 第42行会抛出NullPointerException 而44行会抛出ArithmeticException
在主函数里面有一点要进行说明 就是49-53行 向Restart发送了100条RESTART信息 这会使得RestartActor抛出NullPointerException
这里粘贴一部分的输出结果
1 | preStart hashcode:1062883844 |
第一行preStart表示RestartActor正在初始化 注意hashcode为1062883844
接着遇到了NullPointerException 根据自定义的策略 这将导致它重启
因此 就有了preRestart 因为preRestart在正是重启之前调用 因此HashCode还是1062883844 表示当前Actor和上一个Actor还是同一个实例
接着就进入了preStart hashcode已经变为了1915158180 说明已经不是一个实例 系统已经为这个RestartActor生成了新的实例 原有的实例因为重启已经被回收 这说明同一个RestartActor在系统的工作始终 未必能保持同一个实例 重启完成后 调用postRestart()方法
实际上 Actor重启后的preStart()方法 就是在postRestart()中调用的(Actor父类的postRestart()会调用preStart()方法)
7.6 选择Actor
在一个ActorSystem中 可能存在大量的Actor 如何才能有效地对大量Actor进行批量管理和通信呢 Akka为我们提供了一个ActorSelection类 用来批量进行消息发送
下面只写示意代码
1 | for(int i=0;i<WORDER_COUNT;i++){ |
上述代码 批量生成了大量Actor 接着 我们要给这些worker发送信息 通过actorSelection()方法提供的选择通配符 可以得到代表所有满足条件的ActorSelection 最后通过这个ActorSelection实例 便可以向所有worker Actor发送消息
7.7. 消息收件箱(Inbox)
我们知道 所有Actor之间的通信都是通过消息来进行的 这是否意味着我们必须构建一个Actor来控制整个系统呢 不一定需要这么做 Akka框架已经为我们准备了一个叫做‘收件箱’的组件 使用收件箱 可以很方便地对Actor进行消息发送和接收 大大方便了应用程序与Actor之间的交互
在上述代码中 与这个MyWorker Actor交互的 并不是一个Actor 而是一个邮箱 邮箱的使用很简单 在上述代码中 根据ActorSystem绑定了一个Inbox 接着使用邮箱监视MyWorker 这样就能在MyWoker停止后得到一个消息通知 在45-47行 通过邮箱向MyWoker发送消息
第48到59行 进行消息接受 如果发现MyWorker已经停止工作 则关闭整个ActorSystem
7.8 消息路由
Akka提供了非常灵活的消息发送机制 有时候 我们也许会使用一组Actor而不是一个Actor来提供一项服务 这一组Actor组中的所有Actor都是对等的 也就是说你可以找任何一个Actor来为你服务 在这种情况下 为了快速有效的找到合适的Actor 或者说如何更为合理调度这些消息 才可以使负载均衡地分配在这一组Actor
为了解决这个问题 Akka使用了一个路由器组件(Router)来封装消息的调度 系统提供了几种消息路由策略 比如 轮训选择Actor进行消息发送
随机消息发送 将消息发送给最为空闲的Actor 甚至在组内广播消息
WatchActor.java
在上面的代码中定义了路由器组件Router 在构造Router时 需要指定路由策略和一组被路由的Actor(Routee) 这里使用了RoundRobinRoutingLogic路由策略 也就是对所有的Routee进行轮询消息发送 在本例中 Routee是由5个MyWorker Actor构成
当有消息需要传递给这5个MyWorker时 只需要将消息投递给这个Router即可 Router就会根据给定的消息路由策略进行消息投递 当一个MyWorker停止工作时 还可以简单地从其将工作组移出 在这里 如果发现没有可用的Actor 就会直接关闭系统
主函数如下:
RouteMain.java
除了RoundRobinRoutingLogic外 还可以尝试BroadcastRoutingLogic广播策略 RandomRoutingLogic随机投递策略 ,SmallestMailBoxRoutingLogic空闲Actor优先投递策略
7.9 Actor的内置状态转换
在很多场景下 Actor的业务逻辑可能比较复杂
Actor可能需要根据不同的状态对同一条消息作出不同的处理 Akka已经为我们考虑到了这一点
一个Actor内部消息处理函数可以拥有多个不同的状态 在特定的状态下 可以对同一消息进行不同的处理 状态之间也可以任意切换
下面模拟一个婴儿作为例子
BabyActor.java
在上述代码中 使用了become()方法用于切换Actor的状态 方法become()接受一个Procedure参数 Procedure在这里可以表示一种Actor的状态 同时 更重要的是它封装了在这种状态下的消息处理逻辑
在上面这个例子中 定义了俩种Prodcedure 一种是angry 另外一个是happy
在初始状态下 BabyActor没有开心也没有生气 因此angry处理函数和happy处理函数都不会工作 当BabyActor接受到消息时 会用onReceive()方法来处理这个消息
在onReceive()函数中 当处理SLEEP消息时 就会切换当前Actor为angry 如果是play消息 则切换状态为happy
一旦完成状态切换 当后续有新的消息送达时 就不会再由onReceive()处理了 由于angry和happy都是消息处理函数 因此 后续的消息就直接交由当前状态处理 从而很好地封装了Actor的多个不同处理逻辑
由此可见 Akka为Actor提供了灵活的状态切换机制 处于不同状态的Actor可以绑定不同的消息处理函数进行消息处理
这对构造结构化应用有着重要的帮助
7.10 询问模式:Actor中的Future
由于Actor之间都是异步消息通信的 当你发送一条消息给一个Actor后 你通常只能等待Actor的返回 与 与同步方法不同 在你发送异步消息后 接受消息的Actor 可能还根本来不及处理你的消息 而调用方已经返回了
这种模式与我们之间提到的Future模式非常相像 不同之处只是在传统的异步调用中 我们进行的是函数调用 但是在这里 我们发送了一条消息
AskMain.java
上述代码给出了俩处在Actor交互中使用Future的例子
上述代码使用aks()方法给worker发送消息 方法ask()不会等待worker处理 会立即返回一个Future对象
在第34行 使用Await方法等待worker的返回 接着在35行打印结果
在这种方法中 我们间接的将一个异步调用转为同步阻塞调用 虽然比较容易理解 但是在有些场合可能会出现性能问题 另外一种更有效的方法是使用pipe()函数
38行再次使用ask()方法询问worker 并传递数值6给worker 接着不进行等待 而是使用pipe()函数将这个future重定向到另外一个称为printer的actor pipe()函数不会阻塞程序运行 会立即返回
7.11 多个Actor同时修改数据:Agent
在实际开发中 很难避免 多个Actor需要访问同一个共享变量的情况
在Akka中 使用Agent的组件来实现这个功能 一个Agent提供了一个变量的异步更新 当一个Actor希望改变Agent的值时 它就会向这个Agent下发一个动作 当多个Actor同时改变Agent时 这些action将会在ExecutionContext中并发调度执行 在任意时刻 一个Agent最多只能执行一个action 对于某一个线程来说 它执行action的顺序与它的发生顺序一致 但对于不同线程来说 这些action可能会交织在一起
Agent的修改可以使用俩个方法send()或者alter() 它们都可以向Agent发送一个修改动作 但是send()方法没有返回值 而alter()方法会返回一个Future对象便于跟踪Agent的执行
CounterActor.java
上述代码定义了一个累加的Actor 在12-17行 定义了累计动作action addMapper 它的作用就是对Agent的值进行修改 这里简单的加1
CounterActor的消息处理函数onReceive()中 对全局的counterAgent进行累加操作 alter()指定了累加动作addMapper 由于我们希望在将来知道累加行为是否完成 因此在这里将返回的Future对象进行收集 完成任务后 Actor自行退出
程序的主函数如下
AgentDemo.java
上述代码中 创建了10个CounterActor对象 在27-31行 使用Inbox与CounterActor进行通信 第29行将触发CounterActor进行累加操作 第35到45行将等待所有10个CounterAcotr运行结束 执行完成后 我们便已经收集了所有的future 在第47行 将所有的Future进行串行组合(使用sequence()方法) 构造了一个整体的Future 并为它创建onCompete()回调函数 在所有的Agent操作执行完成后 onComplete()方法就会被调用 在这个例子中 我们简单地输出最终的counterAgent的值
7.12 像数据库一样操作内存数据:软件事务内存
在一些函数式编程语言中 支持一种叫做软件事务内存(STM)的技术 什么是软件事务内存? 这里的事务和数据库说的事务非常相似 具有隔离性 原子性和一致性 与数据库事务不同的是 内存事务不具备持久性(很显然内存数据不会保存下来)
在很多场合 某一项工作可能要由多个Actor协作完成 在这种协作事务中 如果一个Actor处理失败 根据事务的原子性 其他Actor所进行的操作必须要进行回滚
下面来看是如何启动一个内存事务的:
STMDemo.java
这里新建了一个Coordinated协调者 并且将这个协调者当做消息发送给company 当company收到这个协调者消息后 自动成为这个事务的第一个成员
下面是代表公司账户的Actor
CompanyActor.java
首先判断是不是Coordinated 如果是Coordinated 则表示这是一个新事物的开始 则表示这是一个新事物的开始 接着
将调用Coordinated.coordinate()方法 将employee也加入到当前事务中 这样这个事务中就有俩个参与者了
调用了Coordinated.atomic()定义了原子执行块作为这个事务的一部分 在这个执行块中 对公司账户进行余额调整
作为转账接收方的雇员账户如下:
EmployeeActor.java
上述代码中 判断消息是否为Coordinated 如果是Coordinated 则当前Actor会自动加入Coordinated指定的事务
在这里 俩个Actor都已经加入到同一个协调事务Coordinated中了 因此当公司账户出现异常后 雇员账户的余额就会回滚
7.13 一个有趣的粒子:并发粒子群的实现
粒子群算法(PSO)是一种进化算法 它与大名鼎鼎的遗传算法非常相似 可以用来解决一些优化问题
粒子群优化的具体解释 注意wiki百科中文内容 需要翻墙阅读
7.13.3 粒子群算法能做什么
粒子群算法应用族多的场景就是进行最优化计算 实际上 以粒子群算法为代表的进化算法 可以说最优化方法中的通用方法 几乎一切最优化问题都可以通过这种随机搜索的模式解决 其成本低 难度小 效果好 因此颇受欢迎
下面就是有一个典型优化的问题
假设有400万资金 要求4年用完 若存在第一年使用x万元 则可以得到效益√x万元(效益不能再使用) 当年不用的资金可存入银行 年利率为10% 尝试制定出资金的使用规划 使4年效益最大
很明显 对于此类问题 不同的方案得到结果可能会有很大的差异
如果使用拉格朗日乘子法对方程组求解 可以得到第一年使用86.19万 第2年使用104.29万 第三年使用126.19万 第4年使用152.69万为这个问题的最优解 总效益达43.09万
由于求解过程过于复杂 需要对12个未知数和方程进行联立求解 比较难以实现
对于这种问题就是粒子群算法的涉猎范围 当使用粒子群算法 我们可以先随机给出若干个满足提交的资金规划方案 接着 根据粒子群的演化公式 不断调整各个粒子的位置(粒子的每一个位置都代表一个方案)逐步探索更优的方案
7.13.4 使用Akka实现粒子群
使用Actor的模式与粒子群算法之间有天生契合度 粒子群算法由于涉及到多个甚至是极其大量的粒子参与运算 因此它隐含着并行计算的模式 其次 从直观上我们也可以知道 粒子群算法的求解精度或者说求解的质量 与参与运算的例子有着直接的关系 很显然 参与运算的粒子数量越多 得到的解自然也就够精确
如果采用传统的多线程的方式实现粒子群 一个最大的问题就是线程数量的可能是非常有限的 在当前这种应用场景中 我们希望可以有数万 甚至数十万的粒子 但是一台计算机 开启数万的线程是不可能的 就是可以 系统的效率也会非常的低 因此 使用多线程的模型无法很好地和粒子群的实现相融合
但Akka的actor不同 由于多个Actor可以复用一个线程 而Actor本身作为轻量级的并发执行单元可以有极其大量的存在 因此 我们就可以使用Actor来模拟整个粒子群计算的场景
代码本身没有什么特别需要说明的地方
首先是俩个表示pBest和gBest的消息类型 用于多个Actor之间传递个体最优和全局最优
其次在PsoValue中 主要包括俩个信息 第一是表示投资规划的方案 即每一年分别需要投资多少钱 第二是这个投资方案的总收益
在Fitness中的fitness()函数返回了给定投资方案的适应度 适应度也就是投资的收益 我们自然应该更倾向于选择适应度更高的投资方案
Bird就是基本粒子
MasterBird是用来管理和通知全局全优的